The TPCC workload "mystery" exposed in the following post was already clarified the last year, and I've presented explanations about the observed problem during PerconaLIVE-2019. But slides are slides, while article is article ;-)) So, I decided to take a time to write a few lines more about, to keep this post as a reference for further TPCC investigations..
The "mystery" is related to observed scalability issues on MySQL 8.0 under the given TPCC workload -- just that on the old aged DBT-2 workload (TPCC variation) I was getting much higher TPS when running on 2 CPU Sockets, comparing to1 CPU Socket, which is was not at all the case for Sysbench-TPCC.
The Mystery
The whole details about initial story you can find in the following article :
ref : http://dimitrik.free.fr/blog/posts/mysql-performance-80-ga-and-tpcc-workloads.html
I'll only remind here the key points about the observed problem to help you better understand the next.
The system used in these test is :
- 48cores-HT Intel Cascade Lake (24cores-HT per CPU Socket)
- OL7, XFS, flash storage (Optane NVMe)
- the workload is not IO-bound (no IO-reads, all data is cached in 128GB InnoDB Buffer Pool (BP))
Sysbench-TPCC
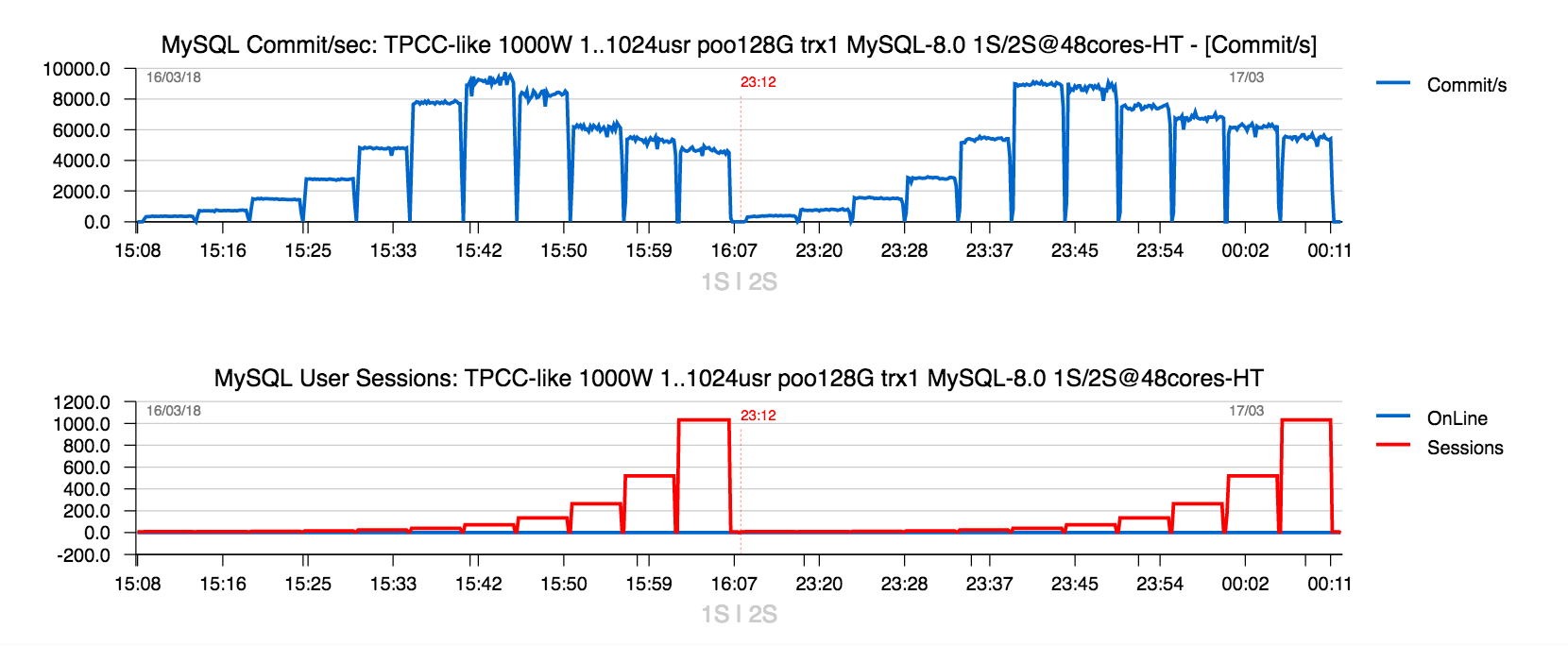
- the graph above is representing obtained TPS levels (Commit/sec, blue line) and reached concurrent users levels (red line, going from 1, 2, 4 .. 1024 users level)
- the left part of the graph is showing the results obtained on 1CPU Socket (1S)
- and the right part, the same workload, but MySQL Server is running on 2CPU Sockets (2S)
- as you can see, the results on 2S is even worse on peak TPS comparing to 1S
- why it's so ?..
- this is because on this workload we're hitting a severe contention on index rw-lock !
DBT2 -vs- Sysbench-TPCC
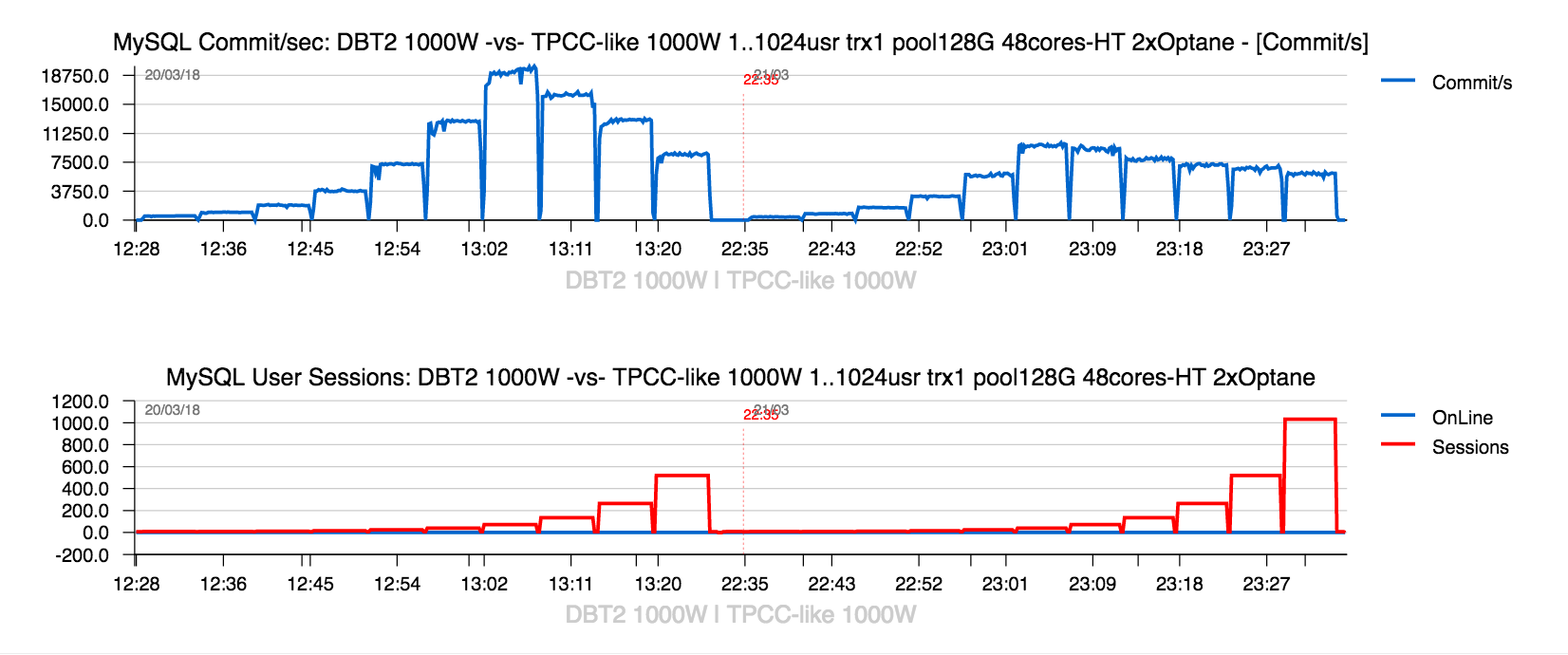
- however, if we comparing TPS results obtained on 2CPU Sockets between DBT2 (on the left) to Sysbench-TPCC (on the right) -- the difference is really spectacular !
- and why TPS is higher on DBT2 ?
- curiously, on DBT2 workload we're not hitting this index rw-lock contention..
And the main question then is "why" we're not hitting it on DBT2, right ? -- supposing both TPCC implementation are mostly doing the same things, how ever it's possible to not see the same on DBT2 ?..
A Long Story Short..
The question remained unanswered for a while, even we could clearly point that index rw-lock contention was involved due massive page splits. Generally every DBMS product has a couple of solutions to lower excessive page splitting (usually resulting in allowing more space in the page to be ahead "pre-reserved", and let rows grow in-page as long as possible, etc.). And MySQL/InnoDB has it also as well.
But my main interest in this story was rather to understand "why" within the same schema constraints and under similar workload conditions these page splits are mostly absent on DBT2, and giving a so hard life on Sysbench-TPCC. Because if there exists any special "trick" or "workaround" which is potentially possible to involve from application side and lower such kind of bottlenecks, then we absolutely need to be aware about ! -- as it can then help so many MySQL users to get yet more additional power from their HW and their apps..
Broken DBT2
Amazing that the first "sign" about what is going odd came from a totally "unexpected" side :
- one day Alexey Stroganov (ex-MySQL, ex-Percona, now Huawei) contacted me with a "strange" question :
- "-- did anyone touched DBT2 code recently ?.."
- (personally I'd never touch DBT2 code at all, I don't like its implementation, so just always used it "as it", so of course I was surprised by this question ;-))
- "-- because DBT2 is broken !!"..
- (how ever I could imagine this ? really broken ? and no one saw it before ?)
- what Alexey found is that in recent DBT2 version someone changed few words in db schema..
- for some strange reasons there was
NOT NULLconstraint added to the column which by TPCC design receivingNULLvalues onINSERT - which is resulted in all "New Orders" transactions to be aborted !
- and which is explaining a total absence of page splits during DBT2 workload, as there is NO new records created at all due this
NOT NULLconstraint ;-))
And once NOT NULL constraint is removed from the column in schema, DBT2 is hitting the same index rw-lock contention because of the same page split problem as Sysbench-TPCC..
This is at least clarified "why" DBT2 was "looking better" and gave me a good reason to finally don't care about DBT2 suite anymore, and rather focus only on Sysbench-TPCC stuff if I need to test TPCC workload.
NOTE : curiously, not all DBT2 instances we're using internally at MySQL were impacted by this
NOT NULLissue, but mine at least was impacted.. Well, at least with Sysbench-TPCC I don't have any kind of surprises right now, which is just fine ! Also, I see the new Sysbench tool as a true "platform" for implementing any kind of test workloads, and hope over a time there will be only more and more other test cases ported to Sysbench..
Finally, WHY ?..
All this story with NOT NULL should already wake-up some "alarms" in our brains on that time, but no.. -- why ? -- this is probably another "mystery" when you're very close to solve the problem, but still not solving it due some other things / problems taking your main attention..
And that's why we're so lucky to have Yasufumi in MySQL Team (ex-Percona, ex-MySQL, and finally MySQL again ;-)) -- after intensive deep digging, Yasufumi found the following :
- "by design" TPCC workload is using
NULLvalue to say "the value is not yet assigned" - and in TPCC case it's all about date columns
- e.g. initially on
INSERTsuch column(s) in row will haveNULLvalue for date - and once the row (record) is "processed", it'll be updated with current date
- so, the
NULLwill be replaced with real date value - and as there was no any space reserved within row data for
datevalue, this will result in page split to give more room to the given row - and so on...
Workaround
Is it possible to avoid the given problem by some "app workflow" implementation ?
- yes, it's possible !
- what do you need is in fact instead of
NULLvalues rather assign someDEFAULTones - this
DEFAULTvalue will then occupy a real space needed for future update - in case of TPCC it was enough just to use a very old date as
DEFAULTto bring the whole workload to the same "realistic" state as before
How different will be your queries, if using DEFAULT instead ?
not much different in fact :
-
INSERT values(.., NULL, ..)will move to ==>INSERT values( .., DEFAULT, ..) -
UPDATE .. var = NULL ..==>UPDATE .. var = DEFAULT .. -
SELECT .. where var IS NULL ..==>SELECT .. where var = DEFAULT ..
NOTE : mind as well there are still several cases in MySQL with
NULLvalues in columns where INDEX on such columns could not be used by Query Optimizer forNULLcriteria, but will always work forDEFAULTvalues..
However, there are still many people are seeing many advantages in using NULL values for their databases :
- the main one is generally about the space
- and, indeed, it'll be hard to use less space in row than
NULL;-)) - from the other side, if you already know that it's only a question of time to see this
NULLvalue to be changed to something "real" (and bigger) -- then you're not saving anything.. - (in fact a "real" value will increase your row size anyway, but additionally you'll also get a page split, and finally using even more space than expected)..
- so, if most of rows in question will stay with
NULLforever, then use ofNULLfor space is justified - but if it's not the case, then using some reasonable
DEFAULTvalue will give higher benefit
Now, comparing TPS results from the "original" Sysbench-TPCC workload using NULL values -vs- "modified" code using DEFAULT instead, we can see the following :
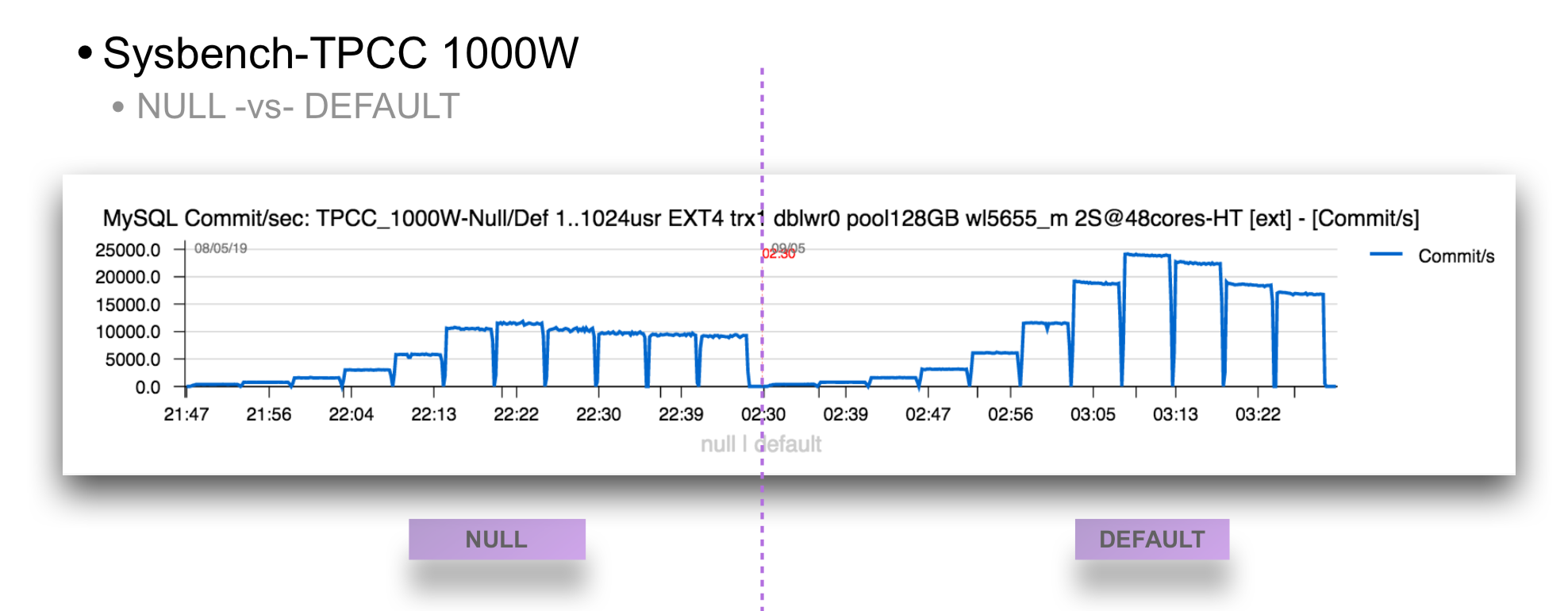
No doubt, the "right side" on the graph is largely winning ! ;-))
Final Results
Keeping this all in mind, here are the results I'm obtaining on "modified" Sysbench-TPCC comparing different MySQL versions and also latest on that time (last year) Percona and MariaDB :
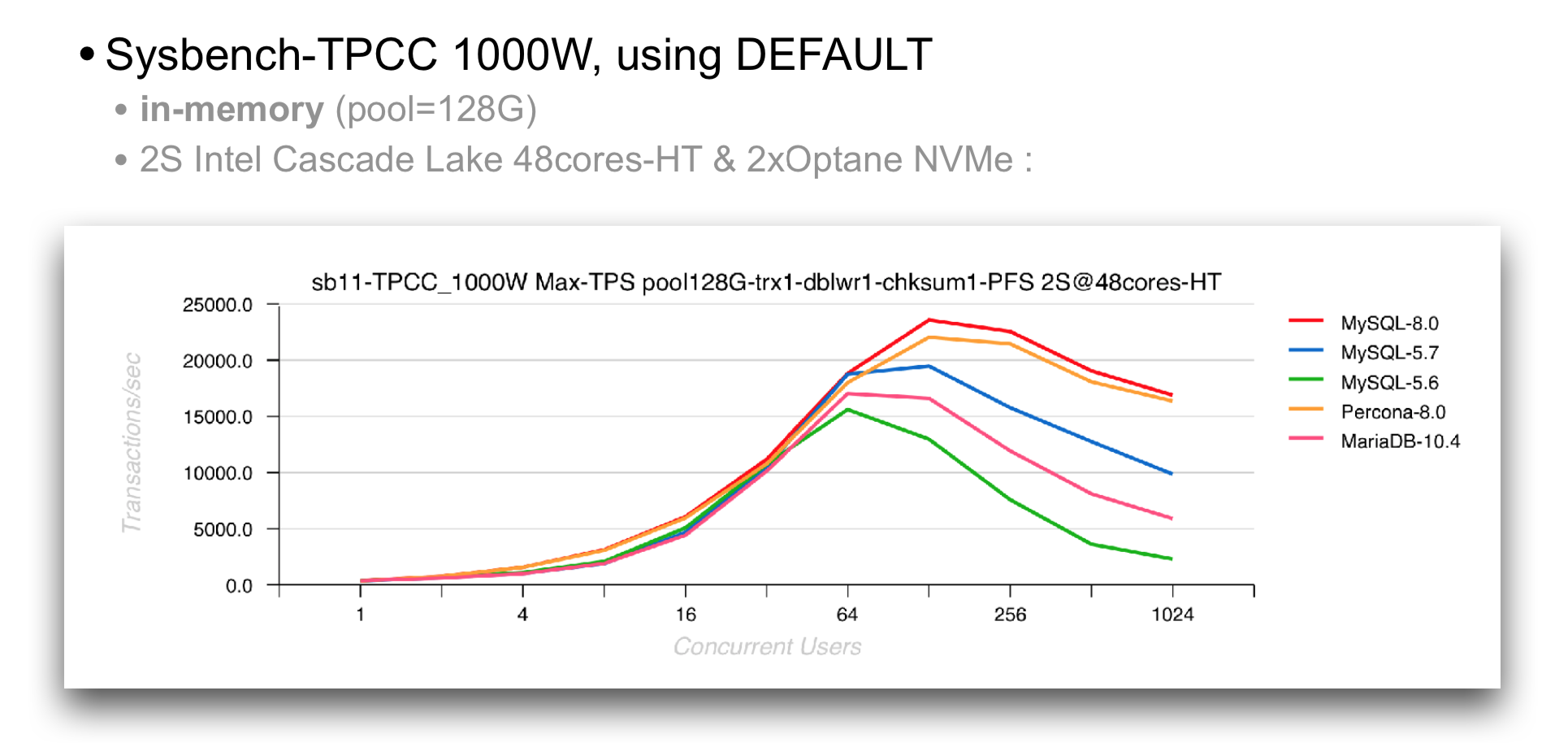
just in case, for ref. the used my.conf in this test was having :
- BP size = 128GB
- PFS=on
- trx commit = 1
- doublewrite = 1
- checksums = crc32
- O_DIRECT
- latin1 charset
- Binlog=off
e.g. all the same settings as from here : http://dimitrik.free.fr/blog/posts/mysql-80-perf-new-dblwr.html if you need all the config details..
SUMMARY
- you can endless debate if using
DEFAULTis not changing the test conditions "as designed" by TPCC -- of course it's changing ! - but if it was your own "production app", how long would you hesitate to change few lines in schema + your app SQL queries to get such a significative performance boost ??
- personally I'd not hesitate even a second, but your decisions are up to you ;-))
Finally, my sincere KUDOS to Alexey and Yasufumi, who continued to dig the issue till the end !! (opposite to others who were just constantly advising me to use 10 or more database schemas in parallel to "hide" the problem and not bother with page split / index lock contention ;-))
So far, yet more work in progress, stay tuned ! And thank you for using MySQL !
Rgds, -Dimitri