This post is following the story of MySQL 8.0 Performance & Scalability started with article about 2.1M QPS obtained on Read-Only workloads. The current story will cover now our progress in Read-Write
workloads..
Historically our Read-Only scalability was a big pain, as Read-Only (RO) workloads were often slower than Read-Write (sounds very odd: "add Writes to your Reads to go faster", but this was our
reality ;-)) -- and things were largely improved here since MySQL 5.7 where we broke 1M QPS barrier and reached 1.6M QPS for the first time. However, improving Writes or mixed
Read+Writes (RW) workloads is a much more complex story..
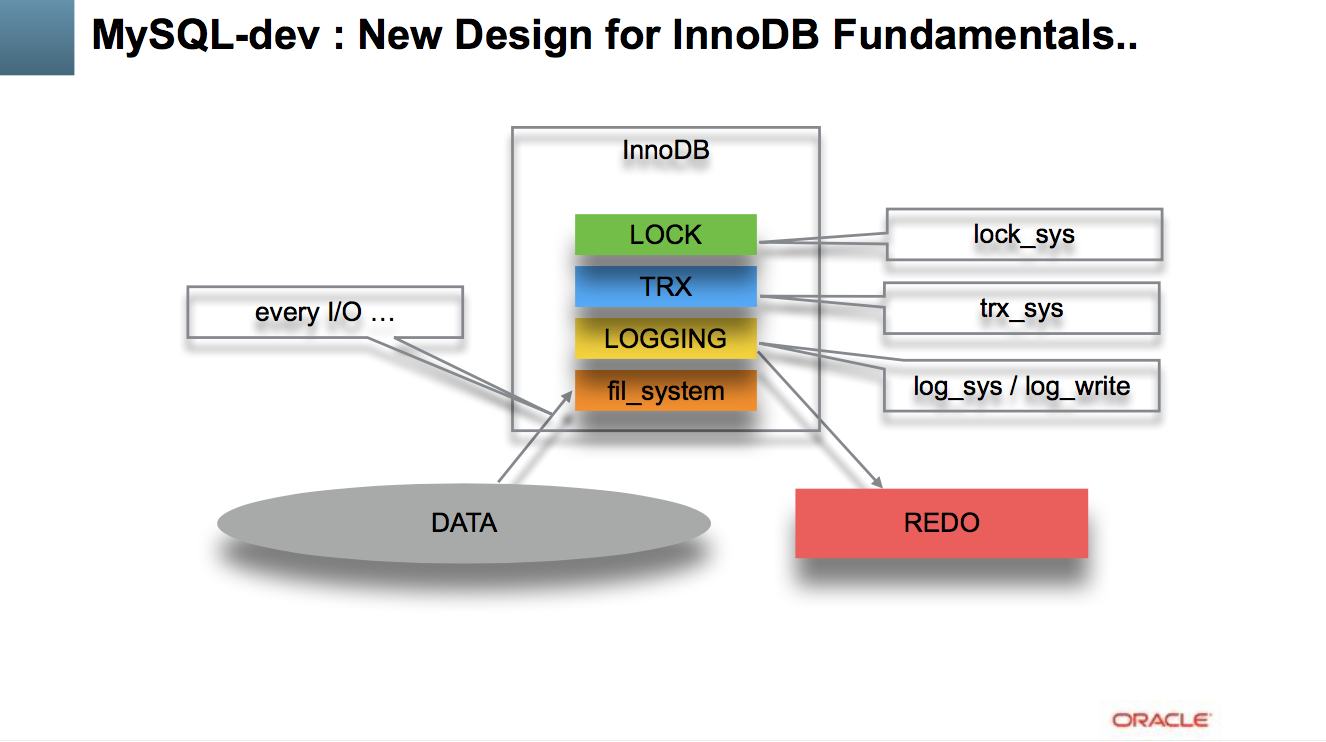
What are the main scalability show-stoppers in MySQL 5.7 and current 8.0 release candidate for RW and IO-bound workloads? - the most "killing" are the following ones :
- REDO log contentions are blocking your whole transaction processing from going faster..
- Transaction (TRX) management becomes very quickly a huge bottleneck as soon as your transactions are fast and/or short..
- internal locking and row locking (LOCK) will quickly kill your performance as soon as your data access pattern is not uniform, etc..
- and yet more, historically as soon as you're involving any IO operations, they all will go via one single and global locking path (fil_system mutex) which will make a use of faster storage solutions (flash) simply useless..
so, it was definitively a time to take our hands on this ;-))
The whole story about is pretty amazing, but I have to be short, so :
- in short : we know exactly what we have to do to get a rid of this all
- we have a working prototype code allowing us to expect pretty important potential gains in RW and pure Write workloads
- the only real problem here is that a road from "prototype" to "production quality" code is much longer than anyone could expect (even me ;-))
- so within MySQL 8.0 GA timeframe we could not deliver all the fixes we have, and we have to go by priority here..
- and the priority #1 from the list of issues mentioned above is for sure going to REDO and IO problems, as the most common show-stoppers for most of RW workloads today
- the 8.0 planned changes are not yet final, but you may already get a first idea about by trying our "preview" MySQL 8.0-labs release
While this article will be mostly about the changes we're doing for REDO.
And in fact the story around InnoDB REDO contains many various surprises :
- historically, very often the perception of how REDO activity is impacting overall InnoDB performance was seen as a balance between performance -vs- security in "trx_commit" tuning settings, e.g. :
- innodb_flush_log_at_trx_commit=1 : flushing (fsync) REDO on every COMMIT
- innodb_flush_log_at_trx_commit=2 : flushing REDO only once per second
- general observations : using innodb_flush_log_at_trx_commit=2 gives a better performance
- conclusion :
- fsync operations are having an important cost, doing it less frequently helps performance
- use innodb_flush_log_at_trx_commit=2 if you want a better performance and can accept to loose 1sec of last transactional activity in case of power off..
- and the main key point in this perception is : "doing fsync to flush REDO is costly"
- while even 20 year ago there were many storage solutions capable to greatly improve write performance (like arrays having battery-protected-cache on controller, or simple write-cache chips, etc.) -- which are particularly will be very efficient with REDO writes which as small and fully sequential..
- however, most of the time the slowness of trx_commit=1 was mostly attributed to "frequent fsync calls" rather to REDO design itself..
- our very fist suspects about REDO design started yet 2 years ago when Sunny implemented a probe dirty patch just to see the potential impact of a different approach in REDO queueing.. => which gave a completely unexpected result : surprisingly observed performance on the same RW workload was better with trx_commit=1 comparing to trx_commit=2..
- after what it became clear that the whole issue is rather related to REDO design, while frequently involved fsync is not representing its main reason but just amplifying the problem..
During the past few years we came with several tentatives to improve InnoDB REDO log design, before to come with an understanding of what exactly do we need ;-)) -- our main target was to
improve performance when trx_commit=1 is used (true security when we do flush REDO on every COMMIT), and from "do less fsync to improve performance" we came to conclusion "let's rather be driven by
storage capacity".
So far, this is how the new REDO design is different comparing to before (very simplified) :

if before users were constantly fighting for permission to write to REDO, in new design they are not fighting anymore :
- User threads are sending their records to Log Buffer (lock-free)
- Log Writer thread is pushing the records further from Log Buffer to FS cache (buffered write())
- after what Log Flusher thread is involving fsync() to flush REDO asap
- if required, User threads are waiting to be notified their records are flushed (in case of COMMIT for ex.)
- the whole chain is asynchronous and event-driven
- we're not trying to write or to flush less or more / or more or less often.. -- all IO activity is driven by storage capacity
- if storage is capable to write quickly (low write latency) => fsync()s will be more frequent, but with smaller data
- otherwise there will be less frequent fsync()s, but with bigger amount of data to flush
- at the end, the whole processing rate will depend only on storage capacity to write REDO records fast enough !
This new model is only the first step in further REDO improvements. Currently by resolving bottlenecks on REDO layer, we're unlocking user threads to do more work, which is resulting in yet more
hot bottlenecks on TRX and LOCK layers. So, there is still a lot of work ahead, and indeed, we're only on the beginning..
However, with new model we discovered few surprises we did not expect on the beginning :

this all related to "low level loads" :
- with old REDO when you have only 1-2 concurrent users, they are not fighting too much for writes
- while with new REDO all the processing work is event-driven and following a chain of events from thread to thread
- and a chain of events between different threads can hardly compete for efficiency -vs- a single thread which is doing all the work alone without any notification waits, etc..
- our final solution for low loads is not yet finalized, but several options are considered
- one of the options : involve CPU spinning in thread waits, which is on cost of additional 20% of CPU usage allowing to catch the same TPS on 1-2 users comparing to what it was with old REDO, but already on 4 concurrent users load reach a higher TPS than before !
The following "dirty" snapshot from intermediate benchmark results on pure UPDATE workload comparing MySQL 5.6/ 5.7/ 8.0-rc/ 8.0-labs/ 8.0-labs-spinning could give you an idea what kind of
headache we may have :
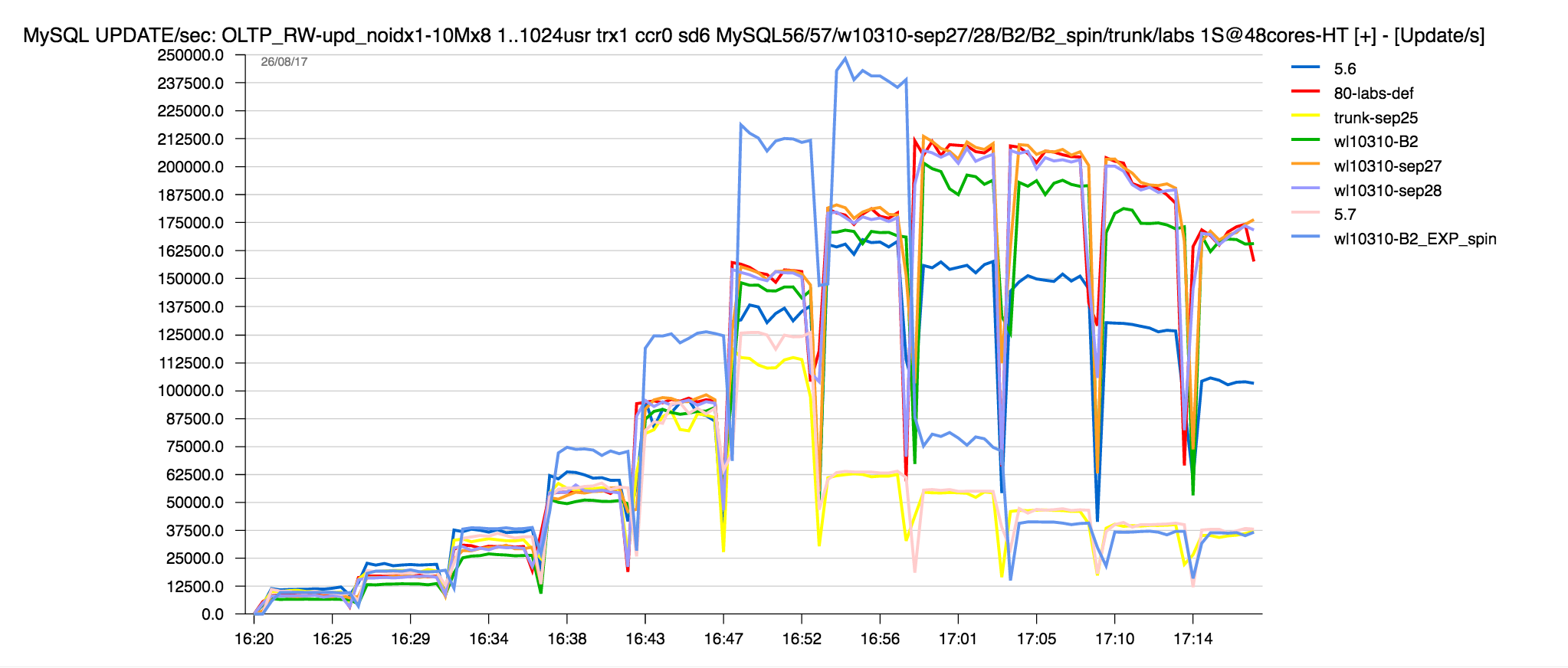
and our main expectation is by combining together all these bits + involving some kind of auto-tuning (or "auto-guided" tuning, etc.) come with something really stable and easy "tunable" for all
kind of loads ;-))
UPDATE : please, don't miss also Pawel's article about how exactly the new REDO log was implemented in MySQL 8.0 GA and why it was not a simple story..
While for the time being, here are few benchmark results we currently obtaining on Sysbench RW workloads :
- Server : 48cores-HT, 2CPU sockets (2S) 2.7Ghz (Skylake), OL7.3
- Storage : Intel Optane PCIe 375GB, EXT4
Sysbench OLTP_RW
- workload : New Sysbench OLTP_RW
- data volume : 8 tables of 10M rows each
- encoding : latin1
- user load levels : 1, 2, 4, .. 1024
- engines : MySQL 8.0-labs, MySQL 5.7, MySQL 5.6
- innodb_flush_log_at_trx_commit=1

Observations :
- 30% gain over MySQL 5.7
- 50% gain over MySQL 5.6
- NOTE: in OLTP_RW workload the majority of queries are Reads, so it's really great to see such a gain, because the main gain on Reads scalability was already reached with MySQL 5.7 ;-)
- on the same time, TRX and LOCK bottlenecks are still remaining..
Sysbench UPDATE-NoIDX
- workload : New Sysbench UPDATE-no_index
- data volume : 8 tables of 10M rows each
- encoding : latin1
- user load levels : 1, 2, 4, .. 1024
- engines : MySQL 8.0-labs, MySQL 5.7, MySQL 5.6
- innodb_flush_log_at_trx_commit=1

Observations :
- 100% gain over MySQL 5.7
- 50% gain over MySQL 5.6
- NOTE: there is no mistakes in the results ;-)
- 5.7 is really that worse -vs- 5.6 on this workload..
- so, we're very happy to fix this gap finally with 8.0 !
The following config settings was used during the presented benchmark workloads :
[mysqld] # general max_connections=4000 table_open_cache=8000 table_open_cache_instances=16 back_log=1500 default_password_lifetime=0 ssl=0 performance_schema=OFF max_prepared_stmt_count=128000 skip_log_bin=1 character_set_server=latin1 collation_server=latin1_swedish_ci transaction_isolation=REPEATABLE-READ # files innodb_file_per_table innodb_log_file_size=1024M innodb_log_files_in_group=32 innodb_open_files=4000 # buffers innodb_buffer_pool_size=32000M innodb_buffer_pool_instances=16 innodb_log_buffer_size=64M # tune innodb_doublewrite=0 innodb_thread_concurrency=0 innodb_flush_log_at_trx_commit=1 innodb_max_dirty_pages_pct=90 innodb_max_dirty_pages_pct_lwm=10 join_buffer_size=32K sort_buffer_size=32K innodb_use_native_aio=1 innodb_stats_persistent=1 innodb_spin_wait_delay=6 innodb_max_purge_lag_delay=300000 innodb_max_purge_lag=0 innodb_flush_method=O_DIRECT_NO_FSYNC innodb_checksum_algorithm=none innodb_io_capacity=4000 innodb_io_capacity_max=20000 innodb_lru_scan_depth=9000 innodb_change_buffering=none innodb_read_only=0 innodb_page_cleaners=4 innodb_undo_log_truncate=off # perf special innodb_adaptive_flushing=1 innodb_flush_neighbors=0 innodb_read_io_threads=16 innodb_write_io_threads=16 innodb_purge_threads=4 innodb_adaptive_hash_index=0 # monitoring innodb_monitor_enable='%'
NOTE:
- yes, I know, PFS is turned OFF, the results comparing PFS=on/off are coming later, no worry ;-))
- with 32GB Buffer Pool the whole dataset is remaining in memory, only writes are going to the storage
- checksums were not set either as they are not impacting in this workload
- (the tests results comparing checksum impact are coming later too)
- other tuning details I'll explain in the next articles..
Also, I've intentionally skipped here all the problems related to InnoDB Double Write Buffer (the only feature protecting you today from partially written pages (except if you're using COW
FS (like ZFS or similar)) -- this feature as it is became a huge bottleneck by itself.. -- our fix was ready yet for MySQL 5.7, but missed the GA timeframe, so was delayed for 8.0, where it met a
list of several pre-requirement before allowed to be pushed, but finally it's only a question of time now to see the fix applied and delivered as part MySQL 8.0 features..
In case you want to replay the same tests, you may follow the same instructions as in the previous
post to setup the scripts and load the test data, then just execute :
OLTP_RW :
cd /BMK for nn in 1 2 4 8 16 32 64 128 256 512 1024 do sh sb_exec/sb11-OLTP_RW_10M_8tab-uniform-ps-trx.sh $nn 300 sleep 60 done
UPDATE-NoIDX :
cd /BMK for nn in 1 2 4 8 16 32 64 128 256 512 1024 do sh sb_exec/sb11-OLTP_RW_10M_8tab-uniform-upd_idx1-notrx.sh $nn 300 sleep 60 done
So far, we're expecting to see a significant progress on RW performance with MySQL 8.0 ! However, regardless positive overall benchmark results comparing to previous MySQL version, we're still
far from scaling on Writes.. -- work in progress, stay tuned, yet more to come.. ;-))
and THANK YOU for using MySQL !
Rgds,
-Dimitri