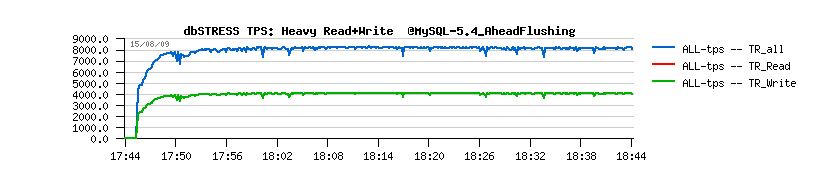
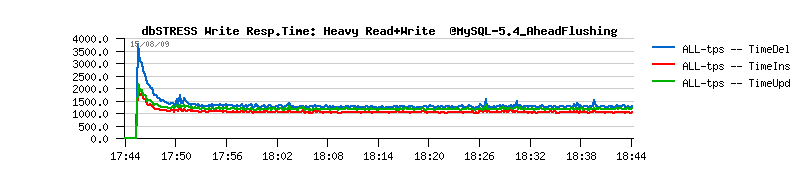
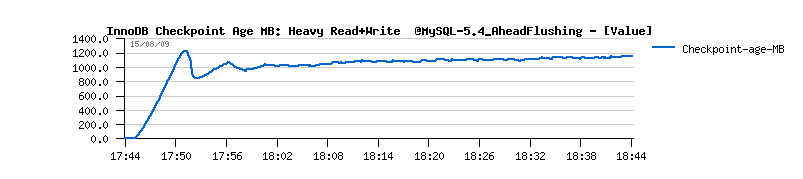
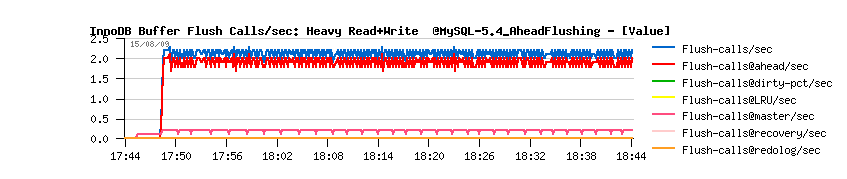
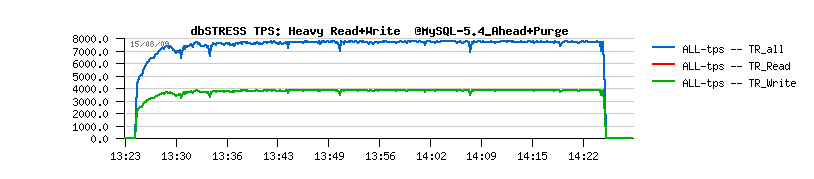
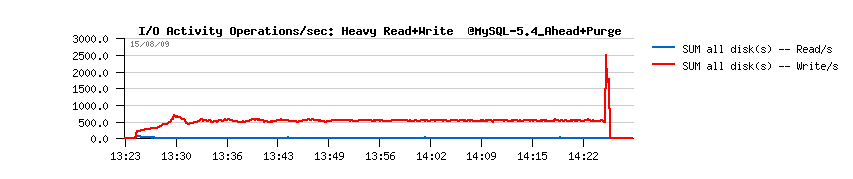
| TPS level drops on the non-stop Read+Write workload |
As you may see, all of them are getting a periodic performance drops. NOTE :
- InnoDB plugin-1.0.4 is using a recently added "Adaptive Flushing" feature
- XtraDB-6 is using the famous Percona's "Adaptive Checkpoint"
So, WHY do they also getting performance drops???...
And let me repeat again - just because during a heavy read+write workload and under current design the Master thread is never leaving the purge loop! and whatever "Adaptive" flushing or checkpoint code, as well dirty page limit check is never reached within a Master thread! - (see for more details my initial report , and next story , but it's not the end yet :-))
Let see more in details how it works..

| How it works... |
By design, InnoDB engine doing the following steps:
- on the database start, according to the total redo log space setting, InnoDB will setup a maximum possible checkpoint age, and the critical limit will be set to something like ~77% (near) of redolog occupancy
- then during a database activity the current checkpoint age is checked permanently - it's counted as a difference between the the current redolog LSN and the older page LSN still present within a buffer pool
- if this difference is outpassing the critical age (77% of redo space) - the "preflush" is involved and dirty pages then are flushed as fast as possible to lower the checkpoint age and avoid a possible database freeze when it'll be out of redolog free space...
- however, the flush on this point is so aggressive that it's blocking database activity anyway!... (well, at least it's due I/O bottleneck, but anyway it's not cool :-))
To get a global view of InnoDB internals I've instrumented the original code with several performance counters and exported them for monitoring via a classic "SHOW INNODB STATUS" command.
| Extention of InnoDB Status command |
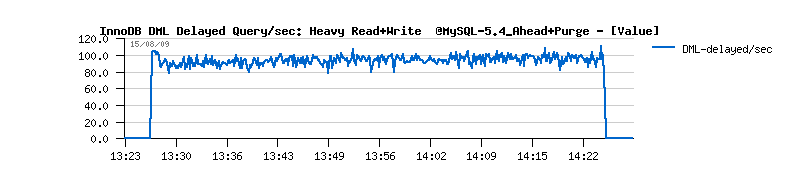
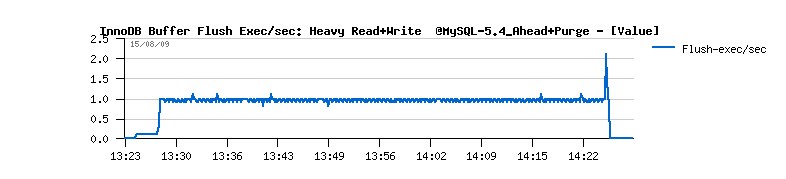
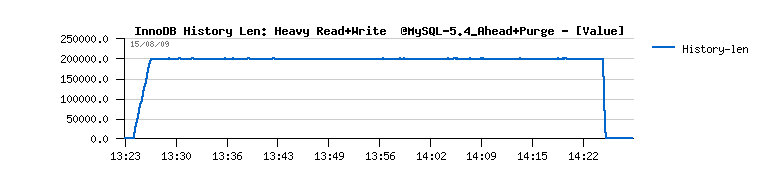
mysql> show innodb status G ... ------------ PURGE STATUS ------------ History len: 2 DML Delay: 0 max: 0 delayed-queries: 0 Purge calls: 15 exec: 1 sleeps: 15 purged-pages: 2 ------------ BUFFER FLUSH ------------ Flush calls: 350 exec: 33 flushed-pages: 13250 Called-by recovery: 0 redolog: 325 LRU: 0 master: 20 ahead: 0 dirty-pct: 5Description :
- History len: is showing a current value of purge history length
- DML Delay: is showing the current value of srv_dml_needed_delay value (in case if purge lag limit was set); max: is the max of srv_dml_needed_delay since the previous show status print; delayed-queries: printing a total number of delayed queries (if any)
- Purge calls: how many times purge function was called ( trx_purge() ), exec: how many purge was really processed (it may be called but have nothing to do), sleeps: how many times purge was able come back to the sleep loop, purged-pages: the total number of purged pages
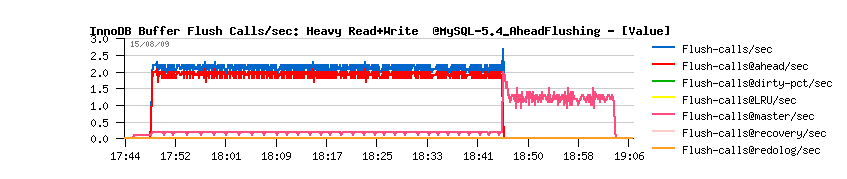
- Flush calls: shows how many buffer flushing was called, exec: how many times buffer flush was really executed (IMPORTANT: if there is already a batch flush is running the call is ignored!), flushed-pages: total number of flushed pages
- Called-by recovery: total number times flush was called from recovery, redolog: from redolog, LRU: from LRU (buffer margin), master: from Master thread (other cases, than dirty pages or ahead), ahead: called from Ahead Flushing code, dirty-pct: called when dirty pages percentage limit is reached
Then I added all this stuff into innodbSTAT Add-On of dim_STAT (see about MySQL Add-Ons here ), and in 5 next minutes was able to graph all InnoDB internals I'm interesting in ;-)
What's cool that a such instrumentation may be reused and compared on any platform (even if you're completely unlucky because you don't have DTrace on your system ;-))
Let's see now what's going on...
| Workload STATs during the test |
Observations :
- once the read warm-up is finished, the read+write test is starting..
- at the beginning of the load everything is going well :-)
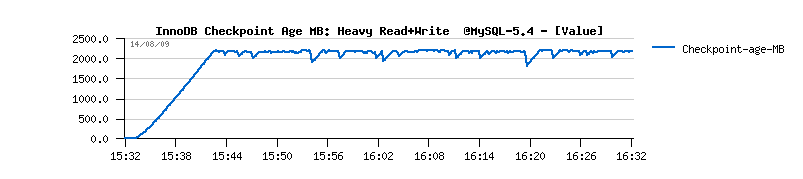
- everything is going well until the checkpoint age is not reaching its critical limit
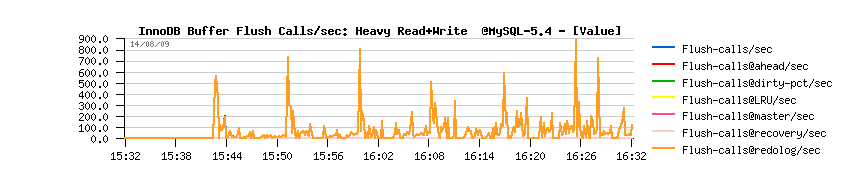
- no flushing at all involved until that moment, but then it jumps to 600 calls/sec from the redolog margin code requiring more free space..
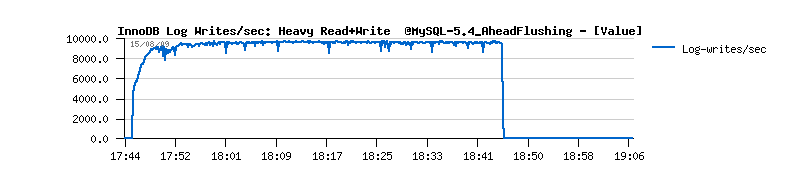
- I/O writes are jumping on the same time
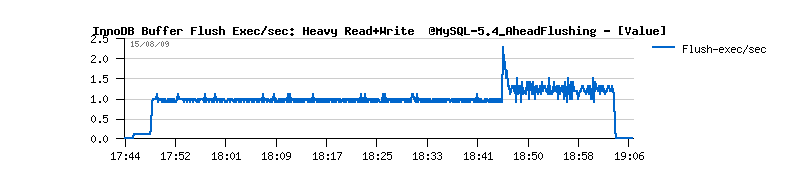
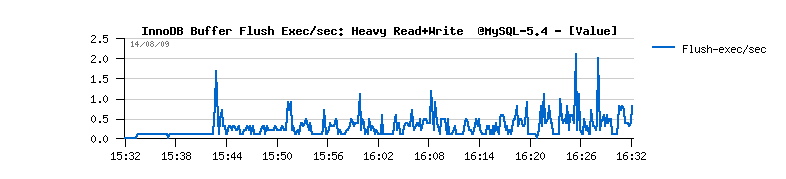
- however you may see there no more than 2 flush exec/sec, when the real buffer flushes happens - means doesn't need to call so often, but more efficient will be preferable ;-)
- involved flushing is still insufficient - every time the critical age limit is reached again the flush burst is involved again and again...
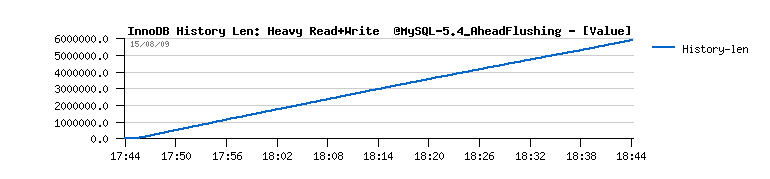
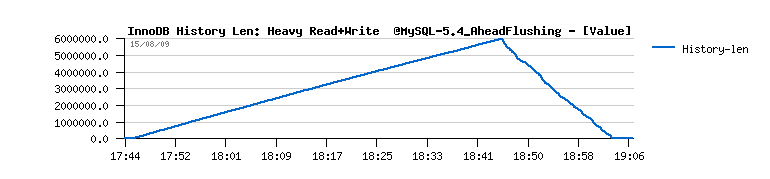
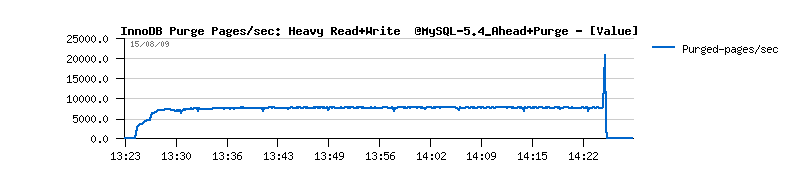
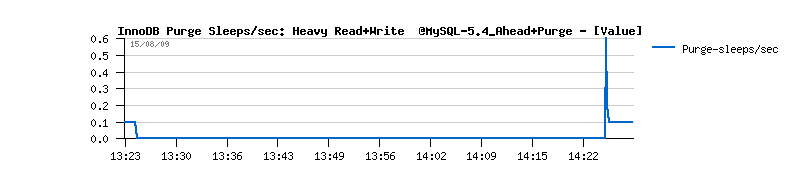
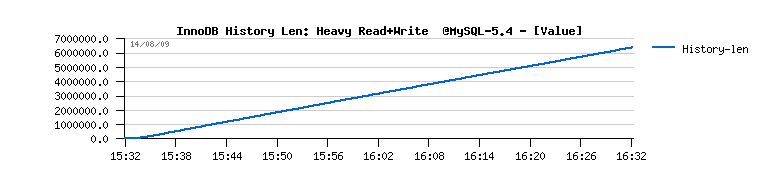
- you may also note the growing history length during all the test, and outpassing 6 millions at the end(!)
- as well you may note that purge is never entering a sleep loop(!) and Master thread is always looping on purge...

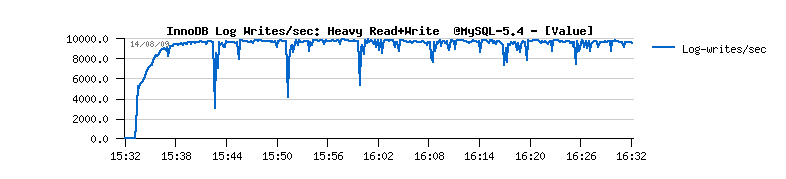
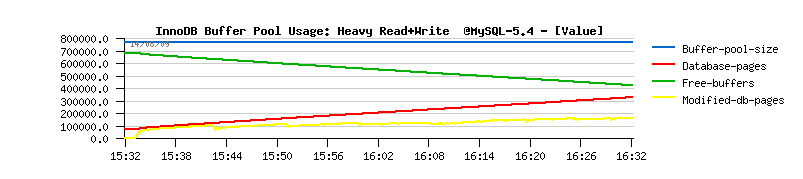
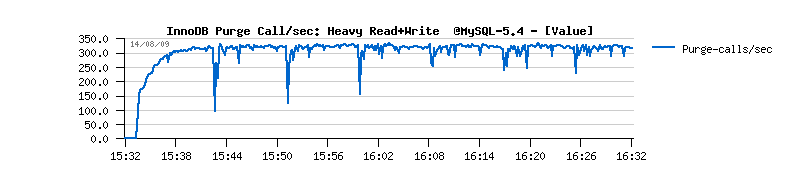

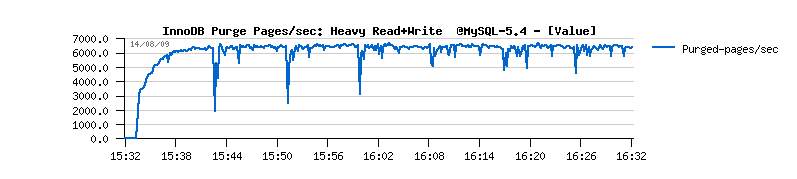

| Final solution |
Initially I've tried to extend a purge loop with ahead flushing to avoid a "furious flushing". Modification is light, but cannot be a true fix because all other Master code should be still executed too :-)And then an absolute radical idea changed everything ! :-)
- Tim Cook came with idea: if it's so, WHY NOT isolate a purge processing withing a separated thread ?..
- and Vince Carbone made an initial code split with separated Master and Purge threads!!!
Why having separated purge thread is absolutely great ?! ;-)
- because after that at least all Master thread code will work as expected in any situation!! :-))
- we may leave purging alone looping forever and not take care anymore! :-))
- Master thread activity become way simpler! :-))
It's for what I always loved Sun - it's a place of innovation !! :-))
This idea inspired me to adapt all my changes to the splitted threads and its current logic is working as the following:
Purge :
- it's a separated thread now, just looping alone on trx_purge() call and doing nothing else ! :-)
- initially by design purge should be involved once per 10 sec, but I've made this interval auto-adaptive: if no work was done during the last loop the sleep timeout is increasing (still respecting max 10sec), and if there was some purge work done - sleep timeout is decreasing (still respecting min 10ms) - works just well and adapt itself to the active workload :-)
Master :
- no more purge! :-)
- no more checks for redo log flush! :-)
- flushing redo log within a 1sec loop (as designed)
- do all other stuff within a 1sec or 10sec loop (as designed)
- for the first time on my workload I saw Master thread checking dirty page percentage limit!!! :-)))
Wow! that's is really great!!! :-))
| Ahead Flushing |
Now, when a dirty percentage limit is really checked, do we still need Ahead Flushing? ;-))And I will say you YES! :-)
Why?..
- currently when a dirty page limit is reached there will be a burst buffer flush with 100% of I/O capacity setting, which may be very heavy; and setting lower I/O capacity than real will be not good as it may be too low to flush fast enough (because the goal is to avoid a critical checkpoint age level)
- it's quite painful to calculate everytime if dirty page limit is set correctly according redolog and buffer pool sizes - it'll be much more better to leave a database engine to take care about, no? ;-)
- there is no a half-force solution: it does no flushing, or then is flushing on 100% I/O capacity :-)
So, yes, we need it!
And with a current model with separated threads both Percona's Adaptive Checkpoint and InnoDB's freshly available Adaptive Flushing are entering perfectly in the game now! :-)) However I wanted absolutely to test a final solution but both "Adaptive" codes were not directly adaptable for MySQL 5.4... So I've made mine :-) and of course I wanted to give it at least a small personal touch :-))
Ahead Flushing :
- may be enabled / disabled at any time live
- if disabled - doing nothing..
- dirty pages percentage limit is verified first - as it's already involving a flushing with 100% I/O capacity no need to check anything else!
- if dirty pages level is still under limit - current checkpoint age is verified - and depending the reached level of the max age, the percentage for flush I/O capacity is calculated (NOTE: differently to Percona's code we try to flush here even if the max checkpoint age is reached! - we absolutely have to leave this critical zone asap, and from what I observed - having flushing involved only from redolog will be not enough here)
- then(!) - we check if the half of dirty pages percentage limit was reached - and if so - we expecting to involve a flushing with 40% of I/O capacity if the previously found percent value (based on checkpoint age) is lower
- we setting a skip sleep flag only(!) if buffer flush was really executed! (not as it's done currently)
Well, it's easier to get a look on the code :-))
| Ahead Flushing code |
if (UNIV_UNLIKELY(buf_get_modified_ratio_pct() > srv_max_buf_pool_modified_pct)) { /* Try to keep the number of modified pages in the buffer pool under the limit wished by the user */ srv_buf_flush_dirtypct_calls++; n_pages_flushed = buf_flush_batch(BUF_FLUSH_LIST, PCT_IO(100), ut_dulint_max); /* If we had to do the flush, it may have taken even more than 1 second, and also, there may be more to flush. Do not sleep 1 second during the next iteration of this loop. */ if( n_pages_flushed != ULINT_UNDEFINED ) skip_sleep = TRUE; } else if( srv_ahead_flushing ) { /* Flush ahead dirty pages to avoid oldest modification age coming too close to the max checkpoint age OR dirty pct coming too close to the limit set by user */ dulint lsn; int pct= 0; lsn = buf_pool_get_oldest_modification(); if( !ut_dulint_is_zero(lsn) ) { pct= (int)( ut_dulint_minus( log_sys->lsn, lsn ) * 100 / log_sys->max_checkpoint_age ); pct= pct < 25 ? 0 : (pct < 75 ? pct - 20 : 80 ); } if( UNIV_UNLIKELY(buf_get_modified_ratio_pct() > srv_max_buf_pool_modified_pct / 2)) { srv_buf_flush_ahead_calls++; n_pages_flushed = buf_flush_batch(BUF_FLUSH_LIST, PCT_IO( pct > 40 ? pct : 40 ), ut_dulint_max); if( n_pages_flushed != ULINT_UNDEFINED ) skip_sleep = TRUE; } else if( pct ) { srv_buf_flush_ahead_calls++; n_pages_flushed = buf_flush_batch(BUF_FLUSH_LIST, PCT_IO( pct ), ut_dulint_max); if( n_pages_flushed != ULINT_UNDEFINED ) skip_sleep = TRUE; } } ...
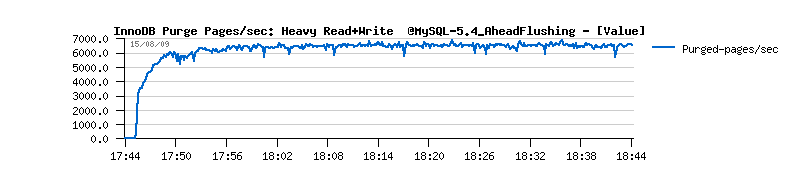
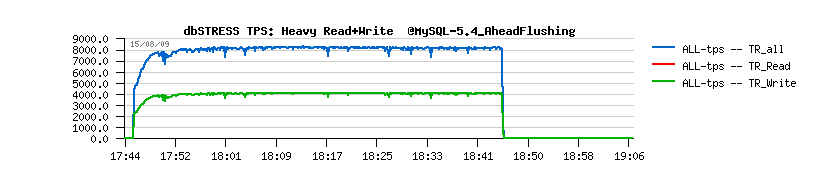
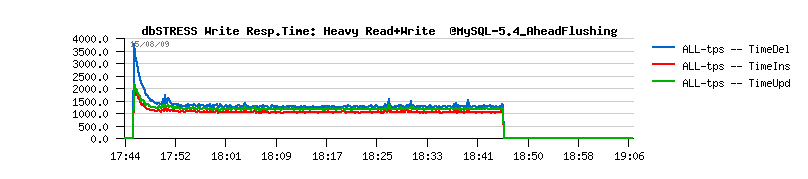
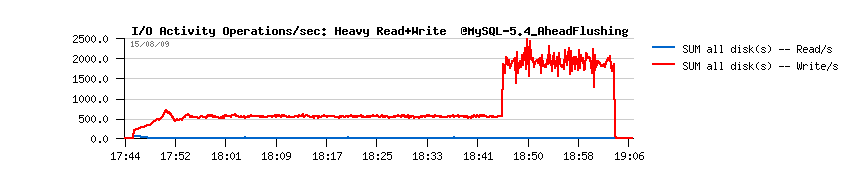
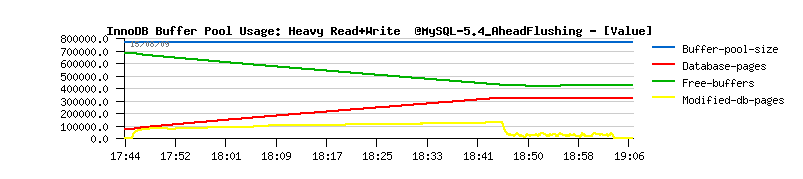
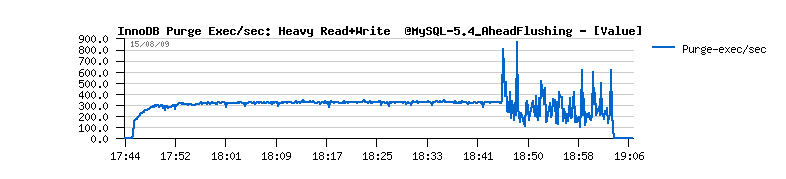
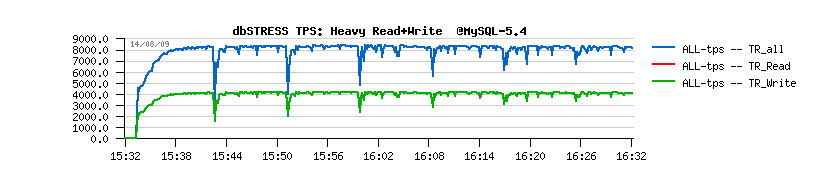
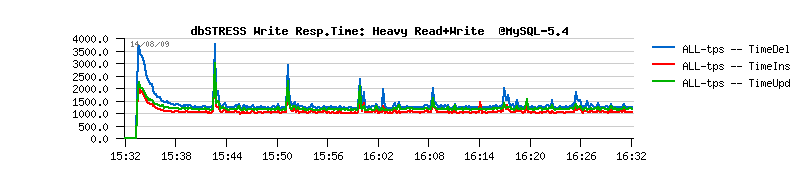
| Workload STATs with the new code |
Observations :
- should I say I'm happy? ;-))
- no more periodic performance drops!
- checkpoint age is staying under 1.2 GB - probably a shorter time in case of recovery? ;-)
- critical checkpoint age is never reached! :-)
- mainly the buffer flushing is involved from Ahead Flushing code, and time to time from the Master thread (misc)
- and still no more than one flush per second is really executed..
Everything goes pretty well now.. except a constantly growing "History len" value...
Ready for the next chapter? ;-)