| 4.1. Probe Test |
As a probe test I'll try to reproduce the old conditions, but within MySQL 5.5 configuration:
- buffer pool instances = 1
- purge threads = 0
- max purge lag = 0
So?.. What about the Buffer Pool pages?..
-
Buffer Pool Usage
- the test is started by the Read-Only warm up, and very quickly all pages are seating in the buffer pool, and the free buffers list level remains stable..
- then the Read+Write activity starts (just before 20:20)
- the dirty pages level (modified pages) is growing but then remains stable..
- while database pages level continue to increase!! (and of course free pages level is decreasing)..
Detailed STATs: Probe Test @
Well, the problem is still here... From the graph above you may see 2 phases:
So, we have in-place UPDATEs, but continue to occupy Buffer Pool with.. UNDO pages? other?..
From the following detailed STAT graphs you may see that History Length is growing too during this test..

| 4.2. Test with Buffer Pool Instances = 4 |
Same test, but now with 4 buffer pool instances.Curiously, it does not change the issue with Buffer Pool pages, BUT dramatically reduces History Length !! Similar results are observed with 8 and 16 buffer pool instances..
-
Buffer Pool Usage with BP instances=4
Detailed STATs: Test with BP instances=4 @
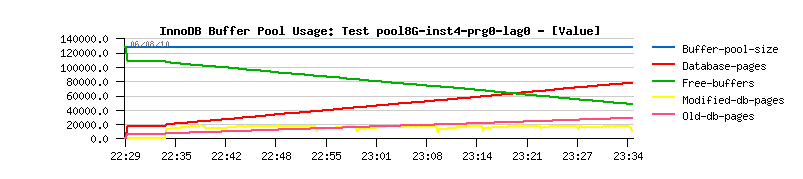
Detailed STATs: Test with BP instances=8 @
| 4.3. Activating Purge Thread |
I did not really expected any improvement by activating a Purge Thread as during all the last tests the History Length remained stable and did not out passed even 200K..But I was happy to be positively surprised, because once the Purge Thread was enabled the Buffer Pool usage start to look like something I've expected to see for the current workload :-))
-
Buffer Pool Usage +purge_thread
Detailed STATs: Test with BP instances=8 + purge_thread @

| 4.4. Higher Workload |
But I was curious now if on the higher workload I'll still see the same stable Buffer Pool usage.. So, I've just start the same test with 2 times more concurrent users ( 64 users now) and observed what I've afraid about - the same issue began again..
-
Buffer Pool Usage +purge_thread with 64 users
Detailed STATs: Test 64 users, with BP instances=8 + purge_thread @
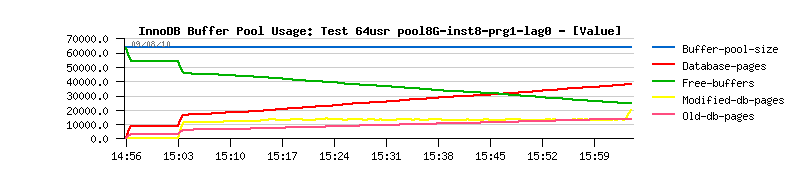
| 4.5. Activating Max Purge Lag Limit |
As during the last test History Length started to grow too, the last try I've decided to do is to see if the Max Purge Lag setting fix may help here.. And finally it helps well :-)) As you can see, the Buffer Pool usage become "normal" again even with double load :-))The max purge lag is set to 400K.
-
Buffer Pool Usage +purge_thread +purge_lag=400K
Detailed STATs: Test 64 users, with BP inst=8 + prg_thread + fixed_lag 400K

Detailed STATs: Test 64 users, with BP instances=8 + purge_thread + fixed_purge_lag 400K