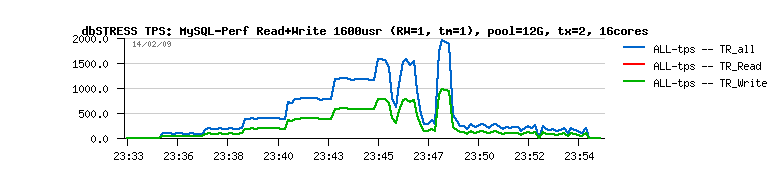
|
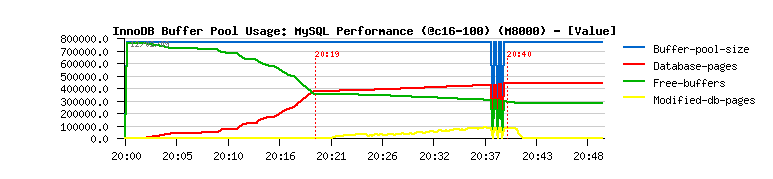
More about the "free buffer issue".
I think there is a wrong logic somewhere (probably a bug or something
is missing in design, etc.) - I know it sounds strange, but let's
think together:
- initially buffer pool is free (800.000 pages)
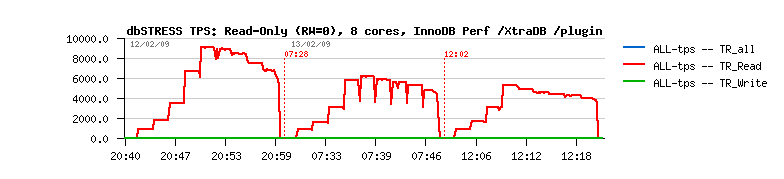
(see graph above)
- after 20min of read-only activity 50% of buffer space is used
to cache data; no reads anymore from the disk; reached max performance
(database-pages = 400.000 pages)
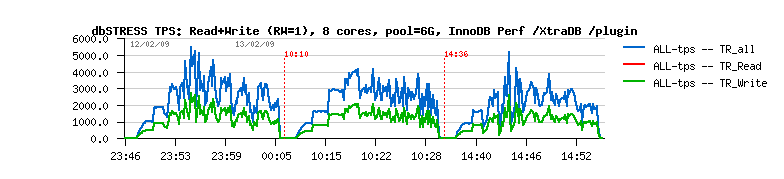
- now writes are added to reads:
- modified-db-pages value is increasing with growing workload (up to 100.000 pages)
- free-buffers value is decreasing nearly proportional
- database-pages value is slightly increasing
- once load is finished:
- dirty pages are fully flushed
- modified-db-pages value is going to zero
- free-buffers value is remaining the same
- database-pages value is remaining the same too
- I still may accept "modified-db-pages" is just a marker, and once it set to zero
it doesn't mean it'll free any buffers, etc. Why not, even the increased value of
database-pages is not completely matching the gap, BUT! During my workload mostly
the same pages are modified all the time! So, whatever happening it should become
stable with time, no?.. However, if I repeat the same read+write load 2 or 3 times
again - I'm out of free buffers!
- On my feeling, there is something wrong going with buffer management generally
and probably garbage is not removed on time (or something going wrong with counters?)
How do you explain it?..
Honestly, today's the most big I/O problem for any database will be a random read .
We have tons of solution to optimize log writes and any writes generally, but
there is nothing to optimize random read except to keep in in the database
cache! otherwise you have to really read data from the storage and it's the most
long I/O operation you may request just because the storage box has exactly
the same problem! :-))
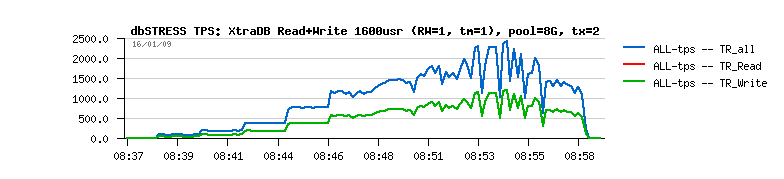
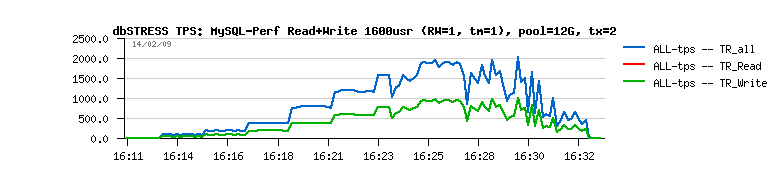
Now:
- innodb buffer is out of free buffers
- getting free pages by removing some data from the "read cache" is the most worse idea here...
- it brings new random reads and killing global TPS level (5ms read is killing comparing to 0.2ms writes)
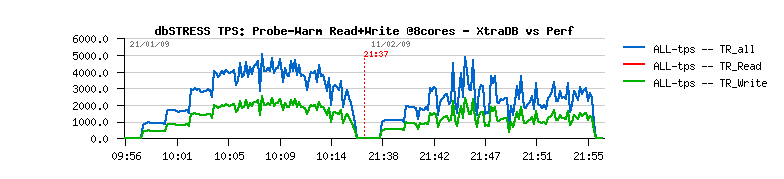
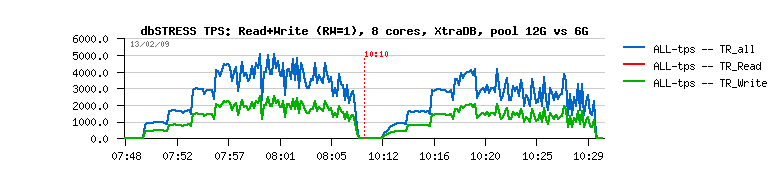
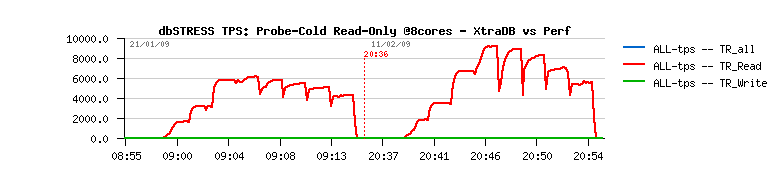
As you may see from graphs, stable 5,000 TPS vs ~avg 3,000 TPS is a huge difference!
Probably we may try an option here saying "I prefer to flush harder and keep
my cache worm"? (what is innodb_max_dirty_pages have to do normally, but it's
not a case)... - and again, there is seems to be something to do with a "priority"
of pages to be removed...
Any ideas?..
|