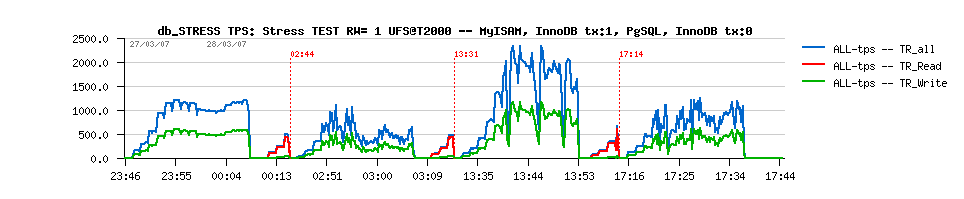
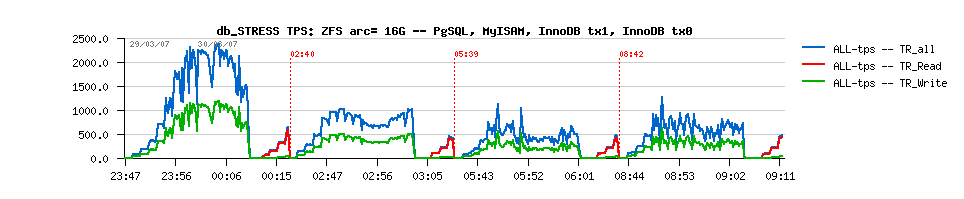
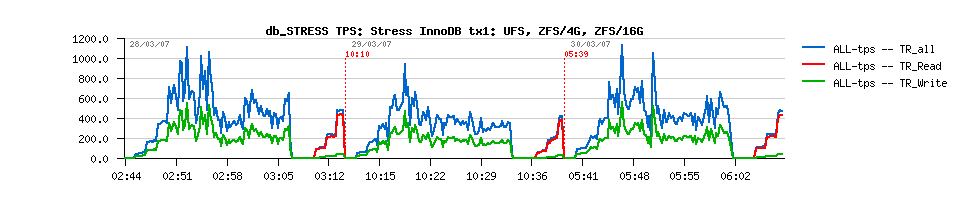
| 2.1. Platform Overview |
System details: 1) T2000 UST1 8cores 32GB RAM
- Solaris 10
- 2 HBA (2Gbit)
- Gbit NIC2) T2000 UST1 8cores 32GB RAM
- Solaris 10
- Gbit NIC3) 4x SE3510 (73GB 12HD)
- primary controller used (2Gbit port)
- two SE3510 connected to V890, and two other to T2000 (#2)
- 2 LUNs: RAID1 (6HD) and RAID5 (6HD)*) Note: V890 was not used in ZFS test due time limitation...

-
SysINFO: T2000 @