« MySQL Performance: Once again about InnoDB thread concurrency... | Main | MySQL Performance: XtraDB-6 & others @dbSTRESS »
Monday, 20 July, 2009
MySQL Performance: Why Ahead Flushing for InnoDB?...
Recently I've done several performance studies to find the most optimal way to fix the "furious flushing" observed during all my benchmarks with InnoDB. The initial report about this work you may find here including initially proposed patches. But analyzing test workloads with the latest MySQL performance build I think there is a need to go more far...
First of all let's me present you the result I've got on the Read+Write workload @dbSTRESS - first part of graph represents the TPS level obtained with MySQL 5.4, and the second part - with the latest MySQL performance build (#46):

This Read+Write workload is running non-stop during one hour within the same conditions in both cases:
- 16 CPU cores
- 32 concurrent user sessions
- innodb_thread_concurrency=16
- innodb_log_file_size=1024M
As you may see, reaching 10,000 TPS over 6,000 represents a huge gain! 66% to be exact. On the same time you may observe even more pronounced periodic performance drops due "furious flushing" (see also previous posts ).
Why it happens?...
The worst case during a high Read+Write activity on InnoDB arrives when the redo log has no more free pages! What does it mean?.. - it means that the oldest redo log data are still referencing on that moment to some modified (dirty) pages which are still kept in the Buffer Pool and these pages are still not flushed to the disk! So, redo log cannot recycle the oldest blocks until the oldest pages are not flushed!.. As you may imagine, what's going next? - At any price redo log should obtain free blocks to continue working (otherwise you may observe a total freeze of your database activity). So at any price it involving dirty pages flushing as fast as possible - it calls buf_flush_batch() function - and from my observations it may call it more than several thousands per second(!) - so we are far away here from respecting a system I/O capacity or other limitations - the goal here is to avoid a database activity freeze at any price!..
However, a short freeze is happening anyway - and as the result we may observe a periodic performance drops (my stats simples on the previous graph where 10 sec - and on the lower time interval it may be seen probably even better)..
Any solution currently implemented to deal with such a problem?..
- you may set InnoDB dirty pages percentage limit to the very low value (innodb_max_dirty_pages_pct) and force dirty pages flushing to be more aggressive
- you may use Percona's "Adaptive Checkpoint" patch (or XtraDB instead of InnoDB as well! :-))
BUT! As I demonstrated previously , on the really high Read+Write workload the Master Thread is never leaving a purge loop, so the innodb_max_dirty_pages_pct settings is never checked, as well Adaptive Checkpoint code (as it currently implemented) is not reached either...
So, what to do here?..
Supposing the purge loop is really necessary by design, my idea was to add a sort of "Ahead Flushing" inside of the purge loop. Why inside?.. - Until while Master Thread is leaving purge loop at least everything is still working as expected. The problems are coming when this loop become infinitive! :-)
My initial solution contained just 2 lines to add into the purge loop:
if (UNIV_UNLIKELY(buf_get_modified_ratio_pct() > srv_max_buf_pool_modified_pct/2 )) { n_pages_flushed= buf_flush_batch(BUF_FLUSH_LIST, PCT_IO(20), ut_dulint_max); }
Which means: if the current level of dirty pages percentage is reached a half of the dirty pages limit setting - flush the next part of dirty pages aligned with 20% of I/O capacity settings.
Of course such a code changes is preferable to be optional and enabled via my.conf settings (for ex.: ahead flusing on/off, starting dirty pages percentage, how much of I/O capacity to use, etc.).. Then spending hours discussing with Mikael the probe patch was born - it's adapting automatically the flushing frequency according to the reached dirty pages percentage level and also respecting the max I/O capacity settings given by the user (Mikael absolutely insisted on this point)... Sounds very good! The only problem - it seems to be too light yet to face the "furious flushing" observed during the high Read+Write workload! And with the latest performance build the flushing become truly "furious" :-)
To go further, instead of the "light" solution I've added my initially proposed changes into the latest performance build and here is it what I've observed (first part of graph is corresponding to the default code, the second one - with added Ahead Flushing code):
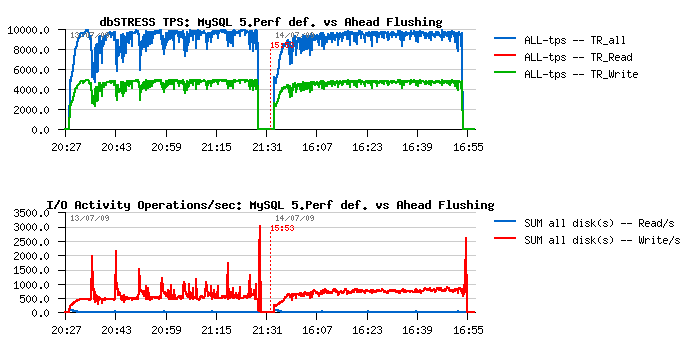
It's still not optimal yet, but looks better then default:
- TPS level became more stable
- same with a writing activity
There are also positive changes on the checkpoint age and log writes stability:

Same for:
- pages activity
- dirty pages level

Well, it's already looks good, but should be much more better :-)
Looking for the optimal solution
- first of all not only the percentage of dirty pages should be checked but also the checkpoint age value! - the redo log may be out of the free blocks much more earlier than the dirty pages level will be reached!
- probably the mix with Percona's Adaptive Checkpoint will be the most optimal?..
- as well more instrumentation on the InnoDB code will be needed to increase internals visibility - for example it'll be nice to add few more statistic values into "show innodb status" saying how many times there was no more space in the redo log, how many times the buffer flush was called, etc...
- also: may we leave the purge loop time to time or not?..
What do you think?...
Any comments are welcome! :-)
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..