« MySQL Performance: Using Performance Schema | Main | EeePC-1005PE & openSUSE 11.2 »
Monday, 12 July, 2010
MySQL Performance: InnoDB IO Capacity & Flushing
This article was initially inspired by Vadim's post on mysqlperformanceblog.com comparing MySQL 5.5.4 and XtraDB under TPCC-like workload. Vadim's post has opened an interesting discussion about InnoDB I/O capacity feature in general, and particularly - tunning / settings regarding 5.5.4 and XtraDB. However, going more in depth I've discovered more interesting things than I've expected initially :-) and here is a kind of summary of my observations..
The following stuff is mainly covering heavy Read+Write workloads as I/O capacity was added to InnoDB to improve page writes rather reading ;-)
First of all - why I/O capacity in InnoDB?..
InnoDB I/O Capacity
Initially InnoDB was designed to flush in background only 100 pages per second. The value of 100 pages was fixed within a code and was not configurable. So, if you have got a storage subsystem able to execute more than 100 writes/sec you were not limited by the storage anymore, but by InnoDB itself..
Google team introduced the "I/O capacity" feature within their performance patches giving a way to adapt InnoDB I/O activity according to a given storage array capabilities, etc. This value of IO capacity entered also in many other maintenance tasks when database needs to decide how many pages should be flushed in background. This feature changed many things and bring some new problems as well :-))
Supposing you've procured a storage array able easily to execute 1000 random writes/sec, so how you can improve your performance now?..
-
Well, before with a fixed 100 writes value the difference was seen
only during a "furious flushing" period (will talk about later)
-
Now, with a new storage you're able to say you can keep 1000
writes/sec, and set innodb_io_capacity=1000. What it'll change? - on
the time of the Google patch this value was mainly used to size dirty
pages flushing. So every time InnoDB reached the max dirty page
percentage setting it started a flush batch with a number of pages
equal to IO capacity setting (as well in other background flushes too
but with a much smaller impact)..
-
So far, with IO capacity any user was able finally to force InnoDB to
process a more or less aggressive flushing of modified data and better
use the available storage subsystem.. But now - what about
performance?.. ;-)
-
From the performance perspective - less you're doing I/O operations
faster you're going :-)
-
On another hand - you cannot delay I/O operations infinitively because
earlier or later you'll need to write anyway and write a huge amount
of pages will be always harder then flush them little bit but
constantly ;-) - of course, your workload may vary and if you know
that after 5 min of hot activity you'll get 20 min of quiet period -
you may probably delay your writes and flush pages during the quiet
period.. - but usually such a programmable situation is not happening
often :-)
-
So, in production environment you know that to avoid write bursts you
need to flush constantly.. - but how much and since which event?.. ;-)
-
If you're flushing too much you'll make your storage busier and your
overall performance lower..
- But which amount of dirty pages you're really need to flush?.. And is there any danger if you're flushing less?.. ;-)
First - does it really matter how many dirty pages you have in your buffer pool?.. ;-)
All changes are reflected in the redo log, so in case of crash you should recover them (but well, if you're crashing too often you probably need to change your HW or OS vendor ;-)) But supposing you've got a solid HW, stable OS, huge RAM, fast storage and don't afraid to drive fast :-) So where is a real danger?..
Usually when you're optimizing a database performance you're not really looking to reach the highest pick result, but rather a stable performance level.. So the main danger will be always to see performance drops during your workload. And when it happens due really growing load - it's one story, but when it happens due wrong configuration or design problems - it's another story ;-)
So far, there are at least 2 most critical situations you may reach "by design" :-)
-
#1) Your buffer pool is small and out of space - most of pages
are dirty and you absolutely need to flush to make a room for other
data.. - Well, such case normally should not arrive because InnoDB is
self protecting to never out pass 70% of dirty pages percentage, but
if your IO capacity is set too low you're not protected ;-) And once
it happens InnoDB has to flush at any price to avoid a global freeze..
and it'll flush without regarding IO capacity setting - it'll simply
involve a full flush, so it'll be written on the highest write speed
as your storage able to sustain.. - So anyway, it'll not be a total
freeze, but not far from that, as under so aggressive writes your
database server will work very slowly. I'm calling it "furious
flushing" :-))
- #2) But if the buffer pool is big enough then the furious flushing may happen again when you're out of free space in your redo logs.. - Having bigger buffer pool will give you a better performance, and for the same dirty pages percentage you'll be able to keep more dirty pages and dispose a bigger gap of buffer pool space.. BUT the max redo log space is still currently limited to 4GB! - and every redo log record referencing a dirty page cannot be recycled until this dirty page remains unflushed.. So once the amount of your changes reached 7/8 of 4GB, InnoDB has no choice - it'll involve a full flush too to avoid a freeze.. - And again, 4GB means you've created your redo log files with a max allowed size (4GB in total) - but with a smaller size furious flushing will arrive much more earlier ;-)
If you still follow me, you'll see that the main problem is coming from redo logs ;-)
There may also arrive another issue due flushing from LRU, but I think its impact will be much less important (or it may be the next issue to fix? - so I'll ignore it for the moment :-))
But well, let's summarize now and go by example:
-
Let's start with a server configured with a buffer pool=500M and redo
log=128M - this configuration will work.. And you'll have all problems
at once, but not really feel them because every full flash will be
still short ;-) So you'll have a low average performance level but
quite stable.. And still feeling you may better use your HW :-)
-
As you have, say, 16GB of RAM on machine, it'll be pity to use only
500M for your buffer pool :-) And once you'll configure buffer
pool=12000M you'll see a huge performance improvement, but mainly on
read operations.. - On the Read+Write workloads you'll only go faster
due faster cached reads, but writes will not go faster.. - Why? -
you'll be still limited by the size of your redo log :-) 128M is too
short and you'll be constantly doing a full flush..
-
Then when you'll try a 3000M redo log you'll see a real improvement
(50% or more)! - but nothing is free.. - with a bigger redo logs once
you're out of redo space your full flushing will be really furious :-))
- On the same time it'll be cool to keep the reached performance level all the time and without performance drops, no? ;-)
Sorry if I'm repeating myself, but a small picture says more - here is a performance level on dbSTRESS with 128MB redo logs:
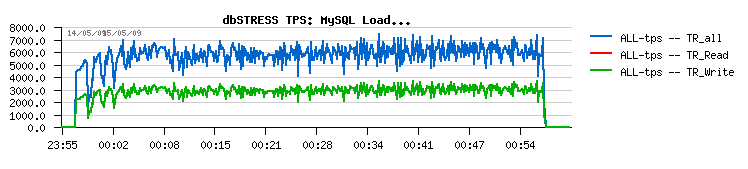
And here is the same workload but with 1024MB redo logs:
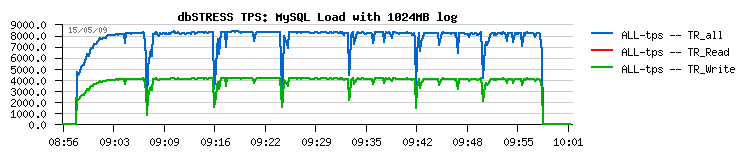
As you see, 8.000 TPS is way better than 6.000 TPS ;-)
BUT - there are huge periodic drops.. And the origin of these drops is out of space in redo logs.
Can it be fixed and how easily ?..
-
You may lower your max dirty page percentage setting and force InnoDB
to flush the modified pages before the redo logs will be out of space,
and IO capacity setting will help you here to adapt your I/O activity
according your workload. BUT - the problem is that there is no direct
dependency between a number of dirty pages and a number of records in
redo logs!.. - So your setting may be still be not low enough to cover
any kind of activity, then by setting max dirty pages percentage too
low you're starting to write too often and slow down your general
performance..
-
The first real solution for this problem was proposed by Percona team
by introducing Adaptive Checkpoint feature. The initial
implementation of Adaptive Checkpoint was released as progressive
flushing: depending on the percentage of redo log occupancy, the dirty
pages flushing was adapted with a relative IO capacity percentage -
less free space is left in redo logs, higher percentage of IO capacity
is used for dirty pages flushing. This solution is still integrated
within Percona's XtraDB and called "reflex".
-
InnoDB then introduced a similar feature which is called Adaptive
Flushing. The solution is based on calculation of estimated speed
of necessary flushing according the dirty pages level and redo log
space occupancy. The estimation obtains finally a number of pages to
flush and this number is compared to the IO capacity setting: the
lower of two values is used then.
- Then, if your workload become really heavy on writes, you'll need a Purge Thread (otherwise either Adaptive Checkpoint or Flushing will not be able to help you because their code will be never reached, so never executed.. - I'll skip details here, but if you want to know why you may read this post ). Just keep in mind that you may need a Purge Thread feature to be sure all things are working right.
So by tuning the IO capacity setting according your workload you may adapt I/O activity on your systems: more or less aggressive writes will be involved on your storage subsystem. As well it's also very useful when your goal is to run several MySQL servers in parallel on the same host (for virtualization or other reasons) and you expect to guaranty a reasonable storage sharing between your MySQL instances. By IO capacity setting you may attribute a sort of quotas for each MySQL server on write activity, etc.
Now, once the preface is finished, let's go back to the Vadim's article :-)
XtraDB & IO capacity
Vadim in his post pointed on a quite curious situation observed on Percona's TPCC-like workload:
-
On the same workload and similar my.conf settings MySQL 5.5.4
performed less stable comparing to XtraDB..
- Further investigations showed that 5.5.4 become more stable with a higher innodb IO capacity setting (and a bigger buffer pool as well)..
So it means that Adaptive Flushing estimation obtains a higher number of pages to flush comparing to the initially used IO capacity setting... So if the IO capacity is configured lower than it should be for a given workload then InnoDB will not flush fast enough to keep a room of free space in the redo logs and will meet a "furious flushing" every time..
To understand if your IO capacity settings is good enough you may just monitor your checkpoint age over a time: if it remains low, stable and not increasing to reach the critical level (ex: stays under 80% of your redo space MB) - it's ok. Otherwise you should increase your IO capacity value.
The problem also that you cannot change it live for the moment.. So if you discover you have to adjust it within your production workload - it may be a real problem if you have to restart your MySQL server.. - except if your familiar with GDB hacking and feel ok to change a global variable of the currently running MySQL process :-) But seems everybody is agree that IO capacity should be a dynamic variable, so I hope we'll see it dynamic very soon :-))
Another helpful features will be also nice to have:
-
A counter of "furious flushing" events (e.g. every time when the full
flush is involved due missing free space in redo logs) - it'll
simplify InnoDB monitoring and give you a needed information about
full flushes without needing to monitor checkpoint age..
- Print a current estimated IO capacity value within InnoDB status output to see if there are gaps between estimated and configured IO capacity values..
Seems it'll be easy to add.
However, my attention here was still mainly focused on the one and the same question I've asked myself after Vadim's article: Why having exactly the same (low) IO capacity settings XtraDB is not meeting the same problems as MySQL 5.5.4 ?...
The real answer as usual is coming from the source code reading ;-) - after scanning and tracing XtraDB code under my workloads I've finally discovered that the default Adaptive Checkpoint setting used currently by XtraDB simply don't use IO capacity setting in its formula - it'll simply write as many pages as it estimated! :-)) So it's normal it does not meet any penalties due lower IO capacity setting :-)) The default mode in XtraDB Adaptive Checkpoint is "estimate", and it's implemented currently to write pages without regarding any IO capacity limits/settings (while previously default "reflex" mode is using IO capacity).. - Well, of course the point about how many writes should be involved by InnoDB and should they be limited or remain free of limits is a subject of long discussions (preferable around a beer :-)) But I afraid there will be as many opinions as people :-)) and the most optimal will be probably leave it as an option on configuration setting:
- #1) - writes are limited by IO capacity
- #2) - writes are free of limits and involved depending on activity
- #3) - writes are limited by IO capacity, but IO capacity is auto-incremented by InnoDB in case of high write requests
And the last option (#3) I'll try to use during the following tests :-)
Well, if it became less or more clear with IO capacity impact, there were still several questions regarding MySQL 5.5.4 which did not stop to run in my head and needed to find their answers..
MySQL 5.5.4 and InnoDB Flushing
When we firstly implemented the Purge Thread feature yet in MySQL 5.4 it did not really bring any performance degradation, but only stability improvements:
MySQL 5.4 default:
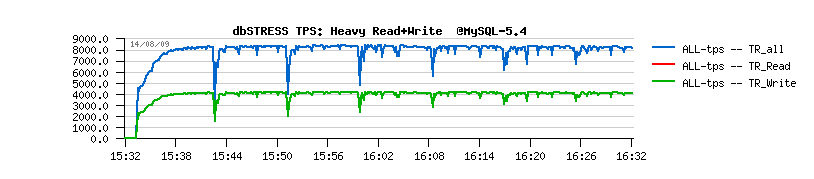
MySQL 5.4 with a Purge Thread:
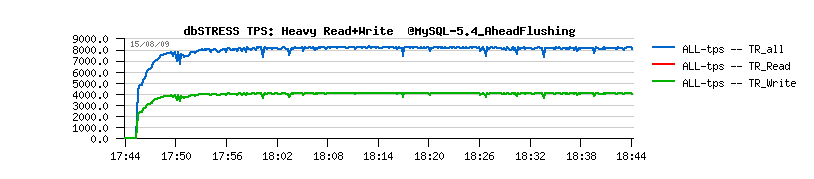
(Ref: MySQL Performance: Final fix for Ahead Flushing & Purge Lag )
Then there are so many changes were introduced within InnoDB code that when the Purge Thread was officially available in MySQL 5.5.4 the things were changed: we started to see decreased performance on the Purge Thread is activated:
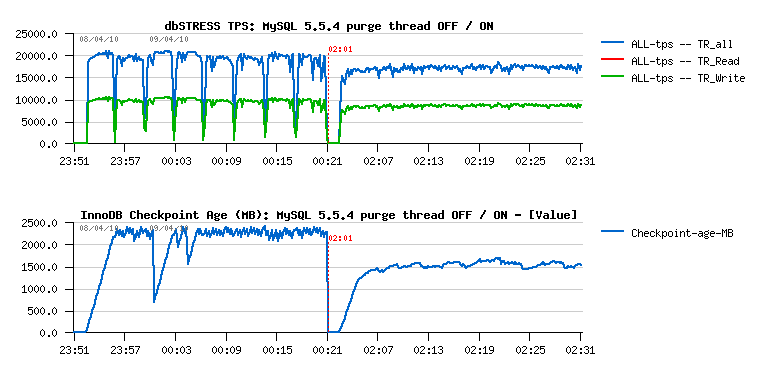
(Ref.: Why Purge Thread in InnoDB?.. )
While I can understand there is a performance drop due bigger processing done by InnoDB once it's doing things right ;-)) but looking on the Checkpoint Age graph I still have impression we're probably flushing too much and observed performance gap may still be reduced...
Then, analyzing my tests with XtraDB I was also surprised that this performance drop in 5.5.4 is significantly higher then in XtraDB:
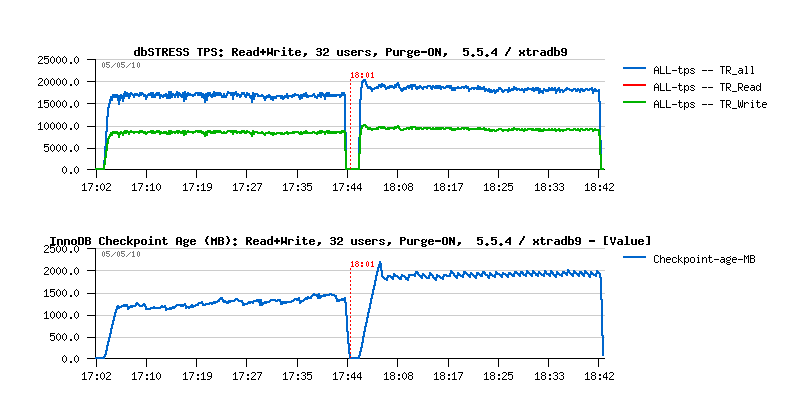
Having 17.000 TPS and 18.000 TPS makes an important difference, specially that having only one purge thread is not yet removing completely a purge lag, and you may need to run two purge threads or have a purge lag fix applied to reach a real stability, but this will also reduce your performance little bit because purging has a big cost! (Ref.: MySQL Performance: Improving Stability for more details)..
And again, looking on Checkpoint Age, there are 2 things coming in mind:
-
Seems we're flushing more than really needed comparing to XtraDB
- Slowly growing Checkpoint Age over a time I don't like at all: it still means there is a danger to not flush enough and meet "furious flushing" (and on more long tests I've observed it by myself, so I'm not presenting other graphs, but just believe me :-))
All these observations make me think there is something wrong in the way we're flushing dirty pages.. But on the same time the code logic in InnoDB don't make me think something was missed.. Which bring me on idea that we simply don't focus on the right direction...
Initially I've started to trace estimation values reported by InnoDB Adaptive Flushing - and it's true, sometimes they were looking too high or too low.. So, I've replaced estimation function by my own formula similar that I've used in 5.4 tests - and it was possible to make InnoDB performing better with a such simple formula, but it make me worry on the same time that such a tunning will be very workload oriented rather universal..
And then getting all things presented above together I've started to look in the root of the problem:
-
Currently what we're trying in Adaptive Flushing is to find a right
number of pages to flush - but is it a right way?...
-
On the same time for some reasons even by flushing an estimated number
of pages we're still not protected to get out of free space in redo
logs and meet the famous "furious flushing"...
-
And then if I monitor my redo log write activity I have only
10-12MB/sec on write activity, which is giving me on x3 of 1GB logs at
least 200 sec before there will be no free space in my redo logs!
- So what I'm doing wrong during these 200 sec to arrive into a bad situation when I don't have a free space anymore?..
Looking on all of these points make me thing that it doesn't really matter how many dirty pages we've estimated to flush.. What is really important - we have just to follow a redo log activity to be sure there is always a free space in redo logs! And all we need is just flush enough to free the tail of the redo logs on the same speed as the redo log is filled :-))
To implement such a solution we have to get a look on how the batch flush function is called within InnoDB:
-
Initially it was buf_flush_batch() function, and since
5.5.4 it's buf_flush_list() function which has only 2
arguments: number of pages to flush and the max age of pages to flush..
-
Curiously that over all history of InnoDB the second argument was
always equal to the MAX possible value (IB_ULONGLONG_MAX) - which
means that when we involve the flush batch there is no guaranty the
most oldest dirty pages will be flushed first! And by flushing an
estimated amount of pages we may still have a tail of redo logs not
freed (well, correct me if I'm wrong, but it's an impression I've
got..)
-
So the idea is simple: instead of IB_ULONGLONG_MAX as max page age
argument give an age based on the redo log tail age ! :-))
- NOTE: going ahead, XtraDB is already using a different value instead of IB_ULONGLONG_MAX within "estimate" option for Adaptive Checkpoint, but on the time I've scanned the XtraDB code I did not really catch this part... - and once my own code worked I was finally able to appreciate the XtraDB solution too! Well done, Percona! ;-))
So far, the Implementation logic looks like this:
-
On every 1sec loop of Master thread the local old/previous LSN is kept
-
On every 10sec the global old LSN is kept and the Redo Log write speed
is recalculated as:
LSN_speed = (LSN_speed + ( LSN_current - LSN_old ) / time_spent ) / 2
-
Then when Adaptive Flushing is involved: if redo log is filled in less
then 10% - do nothing; otherwise the flush batch is involved
-
The flush list function is called as buf_flush_list( IO_capacity,
flush_age ) where:
- IO capacity: is simply all 100% of IO capacity setting
- flush_age: oldest page modification + (LSN_speed + (lsn_curr - lsn_old)) / 2
-
So the Flush Age is always adjusted according the avg redo log
activity observed over a time; then the IO capacity settings is
limiting the number of pages to flush in case there are too much
corresponding to the given age limit..
- Optionally, the IO capacity setting is increased by +100 every time when there was met 10 times the redo log occupancy at 75%..
So what about the TPS results now? ;-)) - I've got even slightly better result comparing to XtraDB, but again - single purge thread is not enough to reach a complete stability, and as mentioned in the previous post , you'll need to have a second purge thread or a purge lag fixed. Solution with a Purge Lag still gives a better result, and by setting innodb_max_purge_lag=400000 we obtaining the following result with XtraDB:
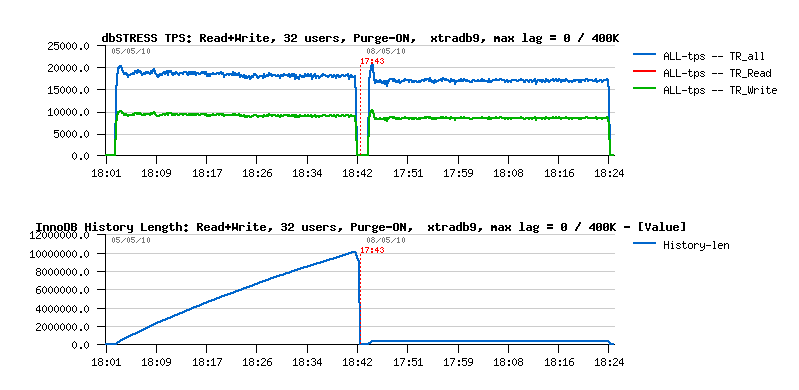
As you see, limiting Purge Lag to 400K is reducing performance (as expected): from ~18.000 TPS we're going to 17.000-17.500 TPS.. However there is a huge changes on the History List length - if before after 40min of activity it grew up to 10M(!!), then now it remains stable at 400K, which is way better for production environment and general workload stability as well..
As before 5.5.4 was worse than XtraDB when the Purge Thread is activated, it was also worse with a Purge Lag limit too.. But now, when the gap is removed, what is the sable result with improved 5.5.4 ?.. ;-))
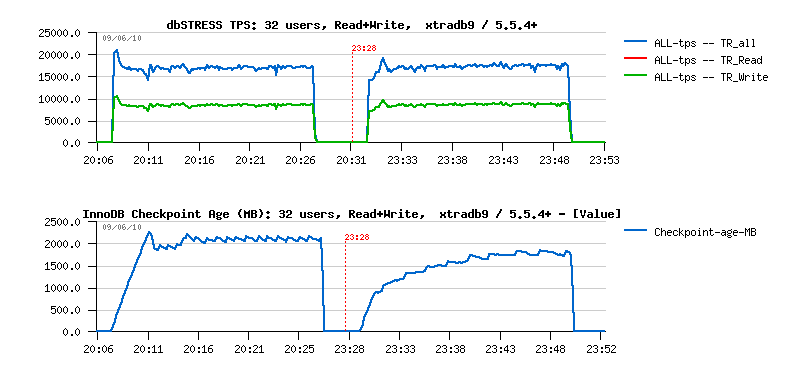
As you can see, over a time 5.5.4 is now the same or even slightly higher then XtraDB! So the proposed solution seems to work better than current flushing estimation in InnoDB.. - but more testing and also on another workloads will be need to find an optimal way ;-))
I've supposed to finish here, but then entered into another mess...
Single User Performance
To get the final results with a growing number of users I've started a classic workload from 1 to 256 users, and observed absolutely strange things having just a one active user:
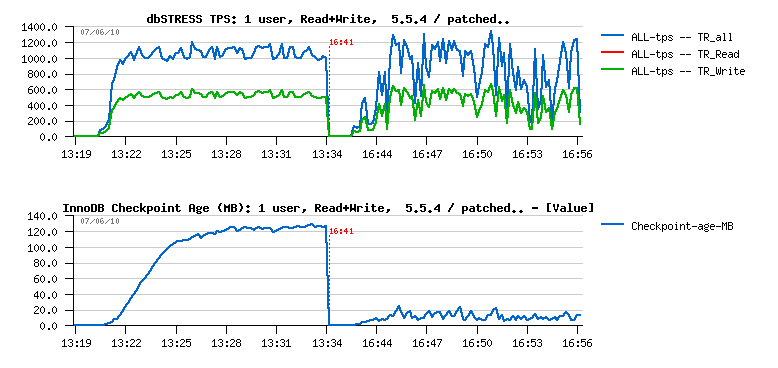
As you can see, the proposed (patched) solution brings a total disorder on workload stability when there is not 32 but only one user is running in the database...
Looking on the Checkpoint Age graph - it's clear we're flushing too much here.. But WHY?...
Once again, the answers are coming from the source code:
- For some reasons, Master thread supposing there was no activity during the last period and going to the background loop(!) while there is still one user non-stop bombarding the database with its queries...
- In the background loop Master thread flushing pages fast supposing there is no user activity and killing my single user performance...
Solution:
-
Don't know if I'm right, but it looks like there are several
bugs/improvements to fix/make here..
-
First of all the IO capacity is not used within a background flush
loop, so it may be a source of performance impact when the storage is
shared between several MySQL instances...
-
Then - the user activity within a Master thread is verified via srv_activity_count
variable, and seems in some cases it remains not increased (or
probably my changes involved such a situation), so by increasing its
value inside of the 1sec loop if there were changes in redo log fixed
the problem!
- Finally - in many places operations with a server activity counter are protected by the kernel_mutex, while all information we need about is to know if there was any changes or no, so doesn't matter how much it was increased, it's just compared to its previous value, and only if it's the same - Master thread is going to the background loop... - So WHY protect it by the kernel_mutex while it's already so hot?... :-))
Applying all these changes, I've got the following results:
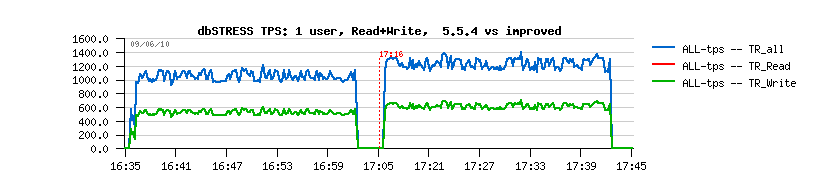
As you see, it's way better!! :-))
And curiously it's even better now comparing to XtraDB:
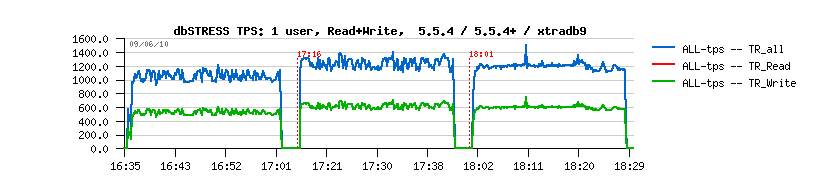
Auto Adaptive IO Capacity
There is still possible that even well tuned IO capacity configuration may meet cases when the IO capacity setting may be lower than needed.. And as I said, it should be configurable and up to user decision if writes should be free of limit or not.. In my case I've tested an auto adaptive IO capacity which is incremented progressively every time the redo log free space become close to critical levels..
Here is a test I've made to see if over the same period of non-stop Read+Write activity 5.5.4+ will still be able to keep the same performance level if I'll disable max purge lag limit (but purge thread active) - if you remember, the result initially for 5.5.4 was 17.000 TPS, and 18.000 TPS for XtraDB within the same conditions - and now for modified 5.5.4+ :
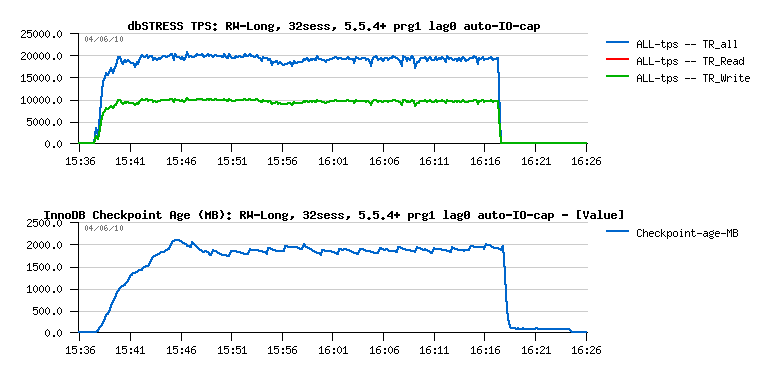
As you can see:
- Performance level remains stable and reaches now higher TPS numbers even than XtraDB :-) and we're not far from the results obtained without using Purge Thread! (similar to what we saw before with MySQL 5.4)
- Auto adaptive IO capacity works well to keep a balance an avoid entering a critical redo log occupancy - BTW, at the end of the test it reached 3600(!) in max - while usually 1500 was enough :-)
- The History Length is reaching 14M(!) at the end of the test, and all these background problems are coming from here - there is more and more unpurged data and every operation become slower and slower.. - Curiously there is not too much more data written to the disks over a time, but InnoDB has to write more over one flush batch to keep enough free space in redo logs...
So far, the work continues, and it's time for vacations now :-))
Any comments are welcome!
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..