« MySQL Performance: post notes after UC2010 | Main | MySQL Performance: Improving Stability »
Friday, 23 April, 2010
MySQL Performance: Why Purge Thread in InnoDB?..
I've got many questions during User Conference about InnoDB Purge Thread feature. And I've promised finally to write a short blog post explaining this feature in details and specially why do you need it :-) Don't know if it'll be short, but hope you'll have less questions by the end of this article.. :-)
So far, during the User Conference we presented the following graph to demonstrate the InnoDB Purge Thread in action:
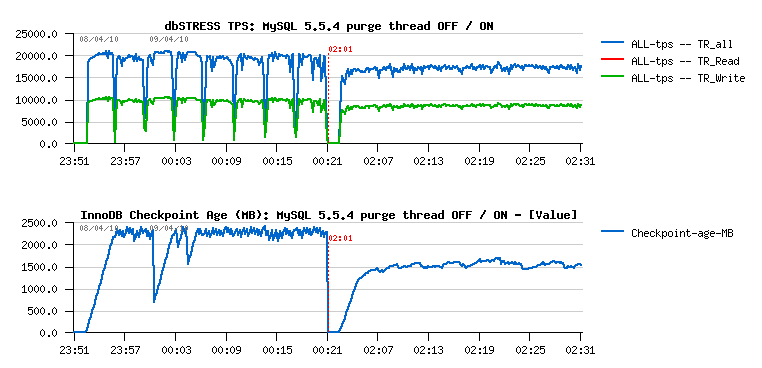
This graph represents 40 min of non-stop activity under dbSTRESS Read+Write workload with 32 user sessions. On the left part of graph you may see the TPS level observed while a purge thread is turned off. And on the right part when it's turned on. From the graph you may see that once purge thread is activated it makes transactional throughput free of all periodic freezes of activity (and seen here as TPS level drops)... And curiously many people manly retain just "ok, it makes the picture more beautiful, but it reduces overall performance, so will keep in mind, but not sure I need it" or "as it reduce performance, I'll avoid to use it, thanks"... The problem that it's not so simple :-) I've wrote many times last year about the purge problem (and if you want all details, the end of the story yo may find in this report ). But in few words - lets get a look on the following chart, it represents the processing logic of the Master thread in InnoDB (also called background/maintenance thread):
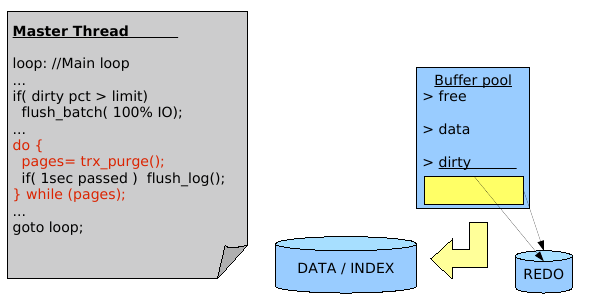
Comments :
-
Master thread is manly looping and doing a list of maintenance tasks
(like involve a buffer flush if the percentage of dirty pages
out-passed a given value; involve redo log every second flush if
needed; involve purging if there is some data to purge; etc.
-
But regarding the purge activity: purge processing is involved from a
loop, and what is important - Master thread will never leave
this loop until there is still something to purge!
-
What does it mean?.. - it means that until you have any data to purge
(and during a heavy read+write transactional activity there will be a
lot of things to purge) the Master thread will stuck on the purge loop
and never process any maintenance tasks which are attributed to
its role! - it means it'll never check the percentage of the dirty
pages you have, and the number of dirty pages will grow within your
buffer pool without any control! - it means all features like adaptive
flushing/checkpoint will be never executed too! - as well many other
maintenance actions will be never reached..
-
What then happens next? - each dirty page is referenced within InnoDB
redo log records; InnoDB redo log is written in a cyclic manner (once
it reached the end of the redo space it starts to reuse its records
from the beginning); to be reused, each redo records should be freed
first; redo log cannot reuse its records until they are still
referencing some dirty pages; as the Master thread is not leaving the
purge loop, no action will be involved to flush any dirty pages at
all; so once your redo log space become filled to its critical level,
InnoDB will try to get a free redo space at any price - and
will involve a massive buffer flushing operation (without regarding to
your I/O capacity setting, etc.) - it needs absolutely obtain free
space to avoid a freeze.. - but such a massive buffer flushing may be
then observed as "stop the world" (largely depends also on your
storage too) - and usually you'll observe a drop on your database
activity similar to those periodic TPS drops I've presented on the
first graph here..
-
You still have a choice here - to avoid such activity drops you may
use smaller redo log files: as your redo space will be smaller, you'll
hit your critical limit faster, so your activity drops will happens
much more often, but will be much more shorter as well - and it'll
give you a kind of illusion of stability :-)
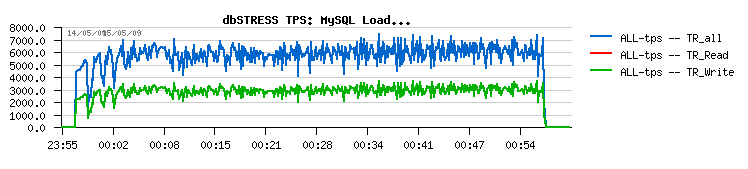
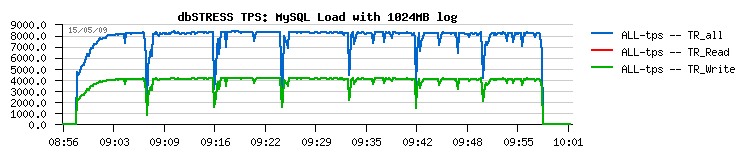
Let's get a look on the following graphs:
128MB redo log :
1024MB redo log :
As you may see:
- 128MB redo log size gives a more "stable" result, without periodic drops
- while 1024MB redo log size gives a more than 30% performance improvement over 128MB :-)
- but anyway, don't forget that even having 128MB will still do not solve the main problem with a Master thread - it'll still stuck on the purge loop and not complete any other assigned to its role tasks...
Well, let's continue :-)
-
How to recognize if you're in a such a situation? - mainly you have to
monitor your History Length value: if it continues to grow your purge
processing is unable to follow your transactional activity.. Then
monitor also the level of your Checkpoint Age - if it jumps too often
to its max critical level while adaptive flushing/checkpoint is set on
- then you're very probably in the similar case too.. Well, the most
easy will be simple to add a counter inside of the "innodb status"
output which shows how many times the free space in redo logs was
missed (and may be some others ;-))
- How Purge Thread helps here? - it completely removes all purge related activity from the Master thread! - so it gives you a guarantee that InnoDB will process as designed! and Master thread will not miss anymore any of its tasks :-) While purge activity is separated into an independent thread and live alone focused on the one single task - purge! :-)

- So, why my performance may decrease when I'm activating Purge Thread?.. - purge processing is quite heavy! - and when purge is done correctly it'll bring an important additional overhead. I'd even say that purge is driving InnoDB performance: until it's done right you'll observe the real performance of your database, otherwise it'll be hard to consider observed performance as longterm... For example, during my experiments with purge code I've accidentally reduced purge activity.. - what was the result? - I've got x2 times better performance! :-) great! but who will need such an improvement? :-) - what will become your database after several hours of activity?? ;-) - first it'll grow with all these unpurged data, then more and more non-valid data will be mixed with real rows making many queries slower and slower.. - don't think you'll be happy finally :-)
So far, after all that said, don't know about you, but all my future benchmarks will be executed only having purge thread settings on :-) And, honestly, if you think well, having purge thread enabled should be a default InnoDB configuration, and probably just the only one.. - but it's my personal opinion.
History
The story with a Purge Thread started for me in Dec.2008 when during my dbSTRESS tests I've observed that any of my dirty page percentage settings was simply ignored by InnoDB, and periodic performance drops happened during every test. Folks from Percona claimed that it's due missing adaptive checkpoint feature, and in Jan.2009 I've made another series of test and demonstrated that the same issue is present in XtraDB too. Then after various testing I went finally into the InnoDB source code and started to trace it in depth to discover that Master Thread is not leaving purge loop.. On that time the same problem was reproduced not only on dbSTRESS workloads, but on DBT2 too. And finally in Aug.2009 with a common effort from Sun/MySQL teams the Purge Thread feature was born, and I've published the patch for MySQL 5.4 that anyone may try and test before it'll come with a next 5.4 release. It was not just an idea, it was a ready for production solution :-) The only problem that from 5.4 branch there was a decision to move to the InnoDB plugin branch on that time, and after all organization and other problems this feature was officially integrated only now, in Apr.2010. But there was nothing "peeked at XtraDB" here.. - it was the result of a long and common work of Sun/MySQL teams. However Percona curiously very quickly forgot from where the solution is coming from.. And I never even think to write it until I did not see this "peeked at XtraDB" list ;-)
Future
There are still several things to improve:
- it'll be fine to have a CPU affinity option for purge thread (in case you have more than 8 cores on your server it'll be more optimal to run purge on a dedicated core and with a highest possible priority)..
- in case if one purge thread is unable to follow a database workload and not purging fast enough - it'll be fine if InnoDB will automatically start another purge thread in parallel (or more depending on demand)..
- and I still have some other ideas.. ;-)
Any comments are welcome! :-)
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..