« MySQL Performance: Call for Workload Scenarios | Main | MySQL Performance: Linux I/O »
Wednesday, 21 December, 2011
MySQL Performance: 5.6.4 @dbSTRESS Benchmark
MySQL 5.6.4 milestone is here and I'd like to share some benchmark results I've obtained with it on dbSTRESS workload.First of all, I was curious to observe a single user session performance (I did not look on it for a while, and there were several persons reporting we got a performance degradation in 5.6 comparing to 5.5 and 5.1).. - Seems it's very workload depending, because on dbSTRESS I've obtained the following:
Read-Only :
- 5.1 : 1800 TPS
- 5.5 : 1750 TPS (but sometimes jumps to 2700 TPS)
- 5.6.2: 2600 TPS
- 5.6.4: 2600 TPS
- 5.1: 2700 TPS
- 5.5: 2600 TPS
- 5.6.2 : 3300 TPS
- 5.6.4: 3300-3600 TPS
The results as they are, I'm planning to profile them to analyze in depth (and periodic jumps to 2700 TPS on read-only in 5.5 are looking confusing). However, few points:
- In 5.6.4 it was possible to suspect the effect of the Read-Only transactions optimization feature , but the results on 5.6.2 is the same or quite similar, and it did not have this feature yet..
- Then, to compare apples to apples, I've compiled all binaries without Performance Schema - so P_S improvements made in 5.6 are not playing here, just pure code base..
Also, a quick workload profiling is already showing me that in some parts of code we're spending more time in 5.6 comparing to 5.5, so there is still yet a room for improvement in 5.6, even it's looking better than 5.5 here ;-))
Now, let's see how the things are going on the multi-user workload.
Few words about the test conditions:
- Server: X4140 12cores bi-thread 2900Mhz, 72GB RAM
- Storage: RAID0 on x2 internal disks, there is an SSD also, but too small to host my database :-)
- OS: OEL 6.1 running UEK kernel
- FS: XFS mounted with noatime,nobarrier option
- Workload: growing from 1 to 512 concurrent users, Read-Only, Read+Update, Read+Write (Write= Delete+Insert+Update)
- Comparing 5.5 and 5.6.4
- Buffer Pool is 32GB, 16 instances
- I'm attentionally not using O_DIRECT here as my internal disks will not be able to follow on random reads (and I'm delegating it to the FS cache), while we may still have some expectation for redo and data writes ;-)
- same for redo flushing: innodb_flush_log_at_trx_commit=2 is used
So far..
Read-Only Workload
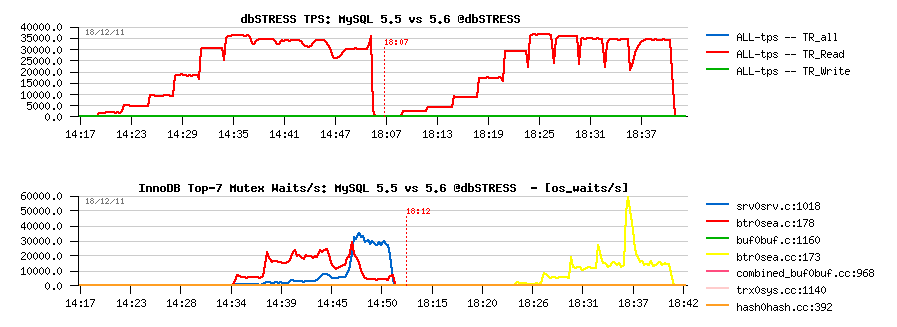
Observations :
- 5.6 is running slightly better here, however keeps the TPS level up to 512 users pretty well
- the main bottleneck is on btr_search_mutex, but it remains stable due limited number of cores on this server (12 cores)
- in 5.5 contention is also combined with kernel_mutex
- NOTE: the trx mutex contention observed before is gone in 5.6 due RO optimization available since 5.6.4! ;-)
- NOTE: it's still need to be fixed for btr_search_mutex - it's abnormal we have this contention while there is no more pages loaded during this period of time into the Buffer Pool. - need to be fixed ;-)
Read+Update Workload
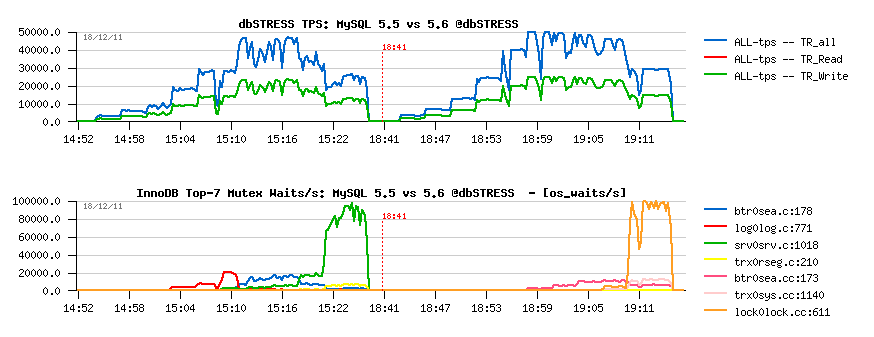
Observations :
- 5.6 is looking better here, and RO optimization feature is slightly helping here too..
- a short presence of contention on the log mutex in 5.5 is signaling here that one moment there was and I/O wait on redo writes in 5.5, but even before it, on the low load, 5.6 is still showing a better performance..
- kernel_mutex + btr_search_mutex waits are the main killers for 5.5
- lock mutex waits are killing 5.6 since 512 concurrent users..
Read+Write Workload
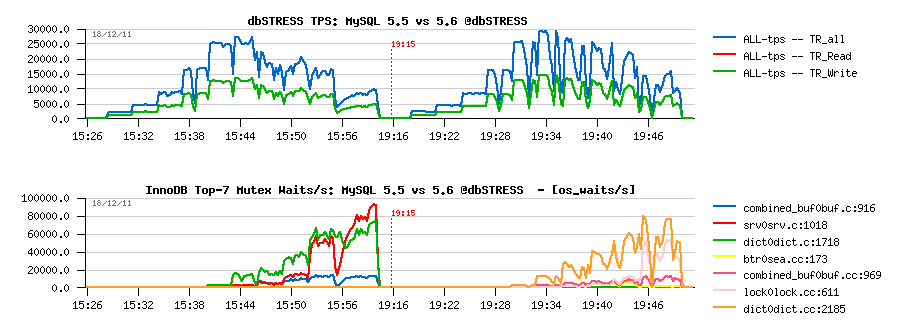
Observations :
- 5.6 is still performing better (while not giving impression of stability..- it's due contentions on my "storage" level ;-))
- index mutex seems to be the main bottleneck here, looks like it's time for me to include also a test with partitions ;-)) but I'd love to see index mutex fixed as well ;-))
Well, not bad at all for this 5.6.4 release, even there are still yet many things to do (like to fix adaptive flushing, etc. ;-))
Then, I was curious if some other stuff may improve performance/stability:
- using small sort and join buffers (32K instead of 2M and 128K respectively) -- no difference..
- using innodb_sync_array_size=32 in 5.6 (instead of default 1) -- no difference..
Next:
-
InnoDB thread concurrency = 24 :
- Read-Only: no difference
- Read+Update: more stable and better performance up to 512 users on 5.6 (due reduced lock mutex contention)
- Read+Write: more stable, but significantly lower performance..
While the impact is very depending on the workload, the feature like that is very welcome here! - the experimental concurrency management in 5.6 should be improved to become production ready. As well having improved Thread Pool extension here will change the things too! ;-)) To be honest, I think even once we'll fix any scalability contentions within MySQL and InnoDB, there will be still a need for a kind of concurrency management (e.g. thread/session pool, resource management) - any HW server + running OS has a limit of a number of tasks it can manage optimally.. - then after this limit you'll always observe a performance decrease ;-)) and the goal fo such a self-manager will be to never out-pass such a limit..
But well, time is pressing, and there was a one feature I wanted to test from a long time - a huge REDO log! (bigger than 4GB).
Read+Update with a bigger REDO size
As a start point I've decided to just replace x3 logs of 1GB by x12 logs = 12GB in total. With 12GB of REDO space there is should be always enough of REDO and the only flushing which should be involved in this case is due dirty pages percentage limit (which is supposed to be quite cool ;-))
But for my big surprise the performance was worse:
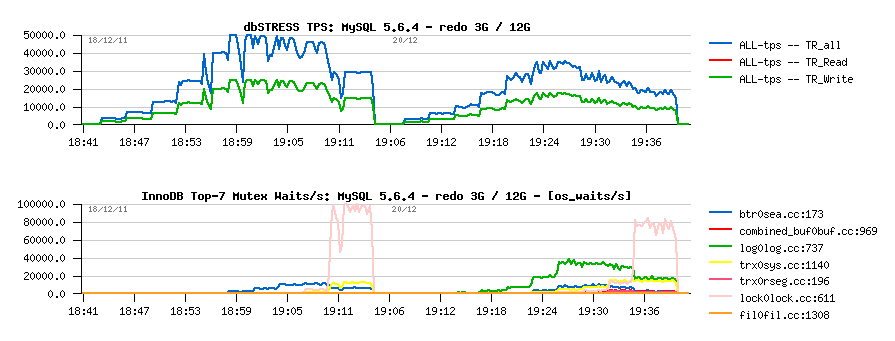
Observations :
- indeed, performance is worse with 12GB REDO vs 3GB..
- such a degradation is explained by log mutex waits..
Hmm.. - is my internal storage became a bottleneck now?? - Let's move REDO logs to the SSD storage (it's small, but quite enough to keep REDO logs ;-))
And it's not really better:
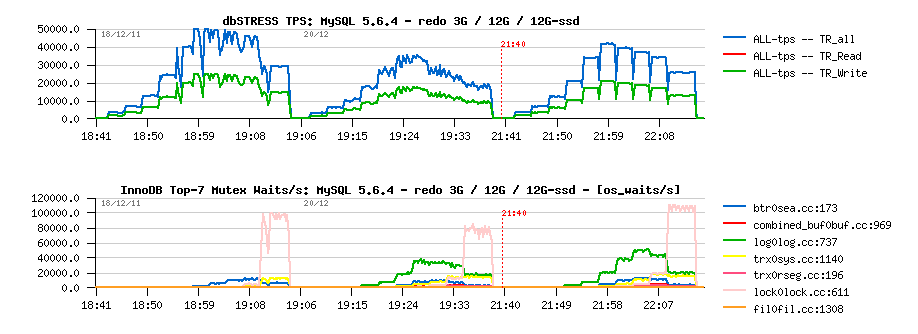
Observations :
- well, it looks very stable since REDO was moved to SSD, and performance is better ;-))
- however, TPS level is still lower comparing to the initial results..
- and WHY I still have waits on the log mutex??? is my SSD not fast enough either?? ;-))
Let's get a closer look on the I/O activity now:
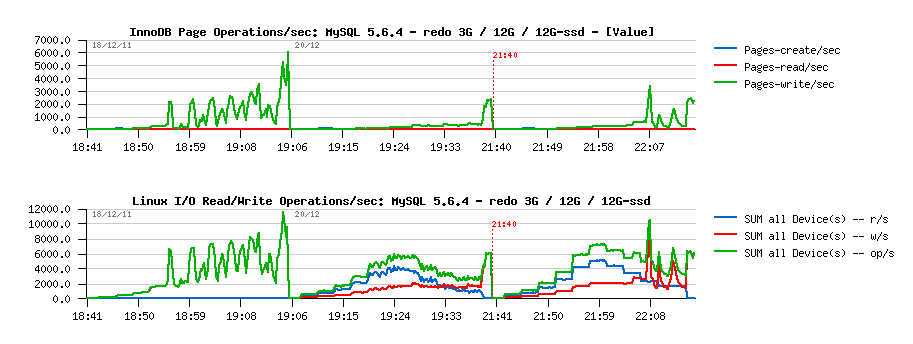
Observations :
- as you can see, InnoDB is reporting no page reads, only writes!
- while from the system I/O stats we can see there were reads present during both last tests (and there is no reads on the initial one)
- why?..
-
the answer is quite simple here:
- the REDO log writes in the current InnoDB code are not aligned to any block size..
- so, most of REDO writes are involving Read-On-Write operation (as the write record is not aligned to FS block size, FS has to read the block first, apply the changes from the record, and then write the modified block to disk)..
- until the REDO size was "small enough", all these reads during Read-On-Write were reading blocks from FS cache ;-))
- now, as REDO was increased to 12GB, once we've finished to write the last log and switching to write to the first one, the first log file will have many blocks already missed in FS cache, so they will be physically read from disk!
- and even SSD is fast, it's not as fast as FS cache sitting in the RAM ;-))
So, here we have an excellent illustration why we have to find a way to write REDO logs with O_DIRECT option (no need to use FS cache for files which are used just for write-only), AND/OR align log writes to the FS block size! (well, in the current design O_DIRECT may have a negative impact as it makes impossible to use a chain: hold_a_lock->write()->release_a_lock->fflush() - with O_DIRECT we'll involve physical write() while holding a lock.. - so such a chain should be redesigned; OR we may simply use a block size aligned writes and involve fadvise() to limit a caching of REDO logs! -- BTW, these points were already discussed with MarkC, VadimTk and all InnoDB team, so it's not something new :-)) but I was surprised to hit this issue so radically :-)) Then, since we're all agree that it should be fixed, it's probably a time to implement it now? ;-))
To go till the end now, let's see if things will be better with 3GB REDO size (as initially), but on SSD:
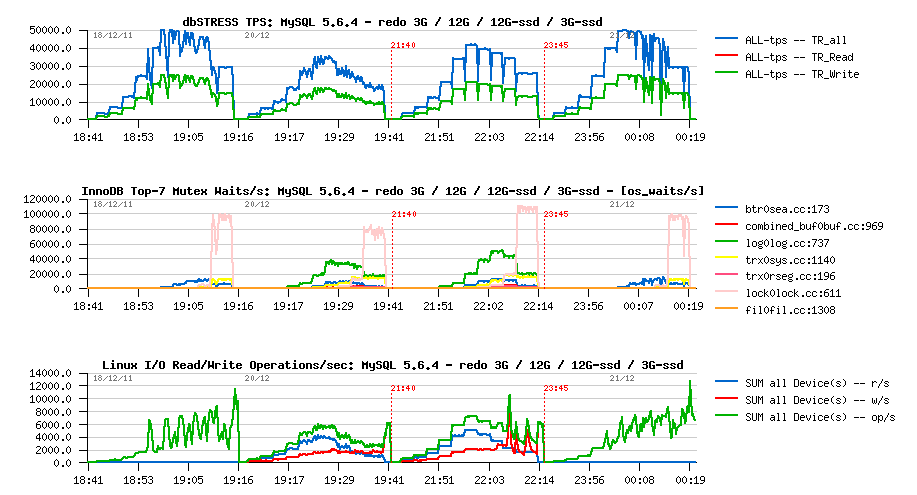
Observations :
- yes, we reached the same 50,000 TPS as before! ;-)
- no more log mutex waits, as expected..
- however, missing some workload stability..
And with 6GB REDO on SSD?.. -
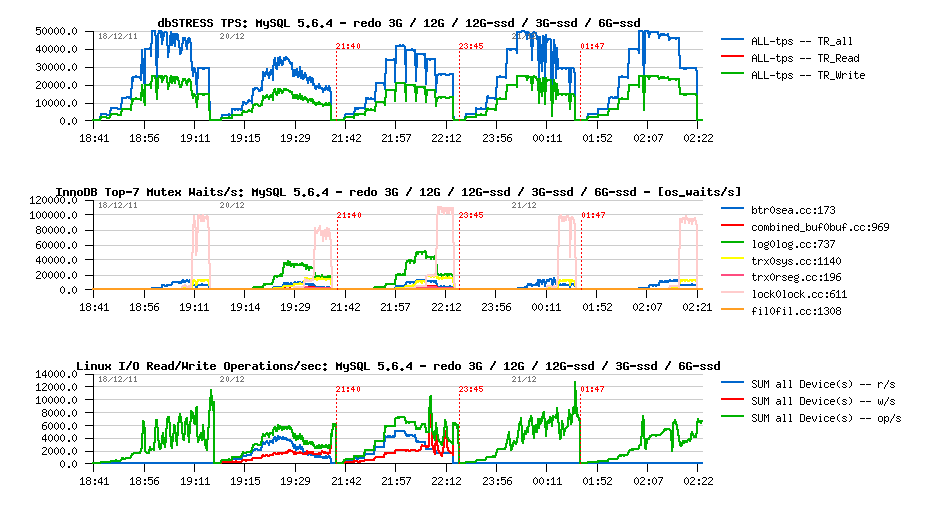
Observations :
- the last result is the most stable from all of we have seen until now :-))
- quite interesting that Checkpoint Age did not out-pass 4.5GB in case with 6GB REDO log..
Seems that improving Adaptive Flushing will be the next step here.. (as well, block size aligned REDO log writes, btr_search_latch and lock mutex contentions ;-))
It's also great to see a growing interest on MySQL 5.6 - db4free.net
is already proposing sandboxes with MySQL 5.6, and I was told that some
other web hosting companies
are actively evaluating MySQL 5.6 adoption now.. Let's see ;-)
Time
for vacations now! ;-))
Some fun stuff..
if you
continued to read until here ;-)) This year is finishing, and there were
many fun events.. - it's a long time now I wanted to share few small
videos from Harmony-2011 Conference (Helsinki, Finland) - it was a
Baltic OUG Conference with MySQL stream, very warm and open mind people,
I really enjoyed it :-)) And here are 2 videos from there:
- Ronald Bradford playing a "Cold War Game" with a Russian guy - HD / MP4
- Opera time @Conference (no words.. just "wow!") - HD / MP4
Happy Holidays! Happy New Year! Happy Vacations! ;-))
Rgds,
-Dimitri
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..