« MySQL Performance: Linux I/O and Fusion-io | Main | MySQL Performance: InnoDB vs MyISAM in 5.6 »
Monday, 05 November, 2012
MySQL Performance: Linux I/O and Fusion-IO, Part #2
This post is the following part #2 of the previous
one - in fact Vadim's comments bring me in some doubts about the
possible radical difference in implementation of AIO vs normal I/O in
Linux and filesystems. As well I've never used Sysbench for I/O testing
until now, and was curious to see it in action. From the previous tests
the main suspect point was about random writes (Wrnd) performance on a
single data file, so I'm focusing only on this case within the following
tests. On XFS performance issues started since 16 concurrent IO write
processes, so I'm limiting the test cases only to 1, 2, 4, 8 and 16
concurrent write threads (Sysbench is multi-threaded), and for AIO
writes seems 2 or 4 write threads may be more than enough as each thread
by default is managing 128 AIO write requests..
Few words about
Sysbench "fileio" test options :
- As already mentioned, it's multithreaded, so all the following tests were executed with 1, 2, 4, 8, 16 threads
- Single 128GB data file is used for all workloads
- Random write is used as workload option ("rndwr")
- It has "sync" and "async" mode options for file I/O, and optional "direct" flag to use O_DIRECT
- For "async" there is also a "backlog" parameter to say how many AIO requests should be managed by a single thread (default is 128, and what is InnoDB is using too)
So, lets try with "sync" + "direct" random writes first, just to check if I will observe the same things as in my previous tests with IObench before:
Sync I/O
Wrnd "sync"+"direct" with 4K block size:
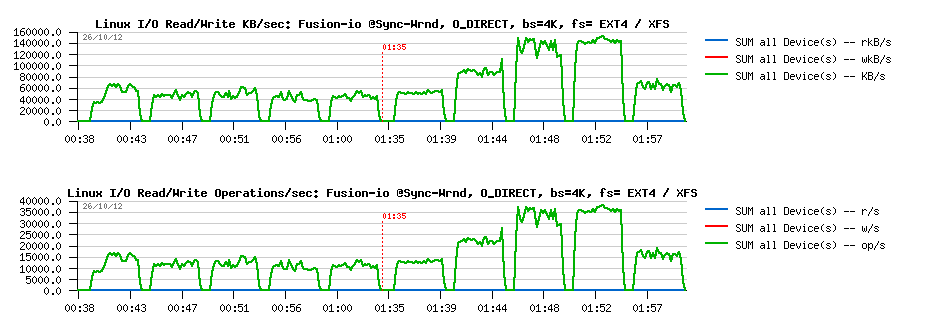
Observations :
- Ok, the result is looking very similar to before:
- EXT4 is blocked on the same write level for any number of concurrent threads (due IO serialization)
- while XFS is performing more than x2 times better, but getting a huge drop since 16 concurrent threads..
Wrnd "sync"+"direct" with 16K block size :
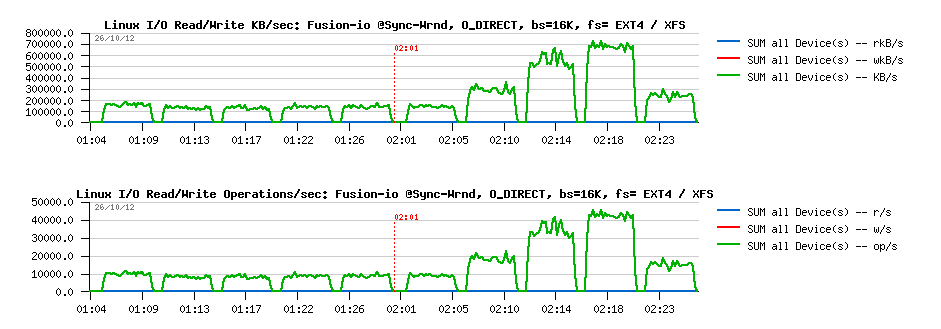
Observations :
- Same here, except that the difference in performance is reaching x4 times better result for XFS
- And similar drop since 16 threads..
However, things are changing radically when AIO is used ("async" instead of "sync").
Async I/O
Wrnd "async"+"direct" with 4K block size:
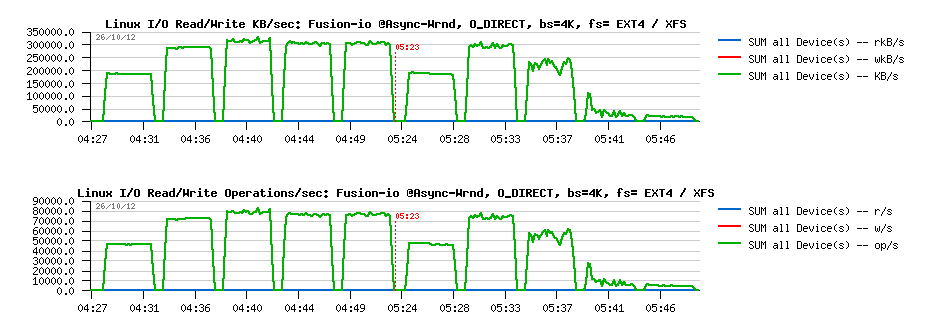
Observations :
- Max write performance is pretty the same for both file systems
- While EXT4 remains stable on all threads levels, and XFS is hitting a regression since 4 threads..
- Not too far from the RAW device performance observed before..
Wrnd "async"+"direct" with 16K block size:
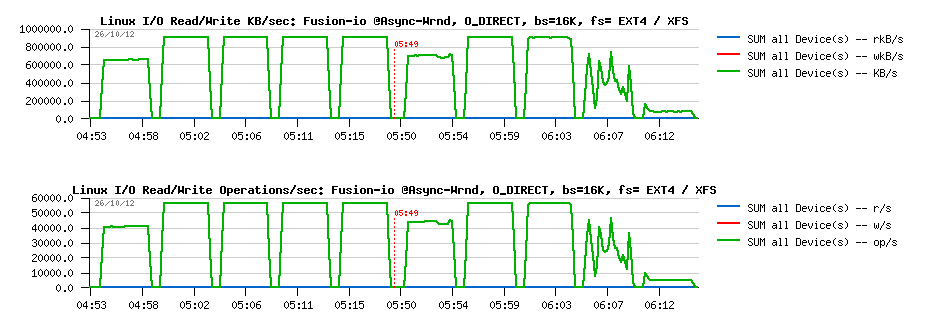
Observations :
- Pretty similar as with 4K results, except that regression on XFS is starting since 8 threads now..
- Both are not far now from the RAW device performance observed in previous tests
From all points of view, AIO write performance is looking way better! While I'm still surprised by a so spectacular transformation of EXT4.. - I have some doubts here if something within I/O processing is still not buffered within EXT4, even if the O_DIRECT flag is used. And if we'll read Linux doc about O_DIRECT implementation, we may see that O_SYNC should be used in addition to O_DIRECT to guarantee the synchronous write:
" O_DIRECT (Since Linux 2.4.10)Try to minimize cache effects of the I/O to and from this file. Ingeneral this will degrade performance, but it is useful in specialsituations, such as when applications do their own caching. File I/Ois done directly to/from user space buffers. The O_DIRECT flag on itsown makes at an effort to transfer data synchronously, but does notgive the guarantees of the O_SYNC that data and necessary metadata aretransferred. To guarantee synchronous I/O the O_SYNC must be used inaddition to O_DIRECT. See NOTES below for further discussion. "
(ref: http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html)
Sysbench is not opening file with O_SYNC when O_DIRECT is used ("direct" flag), so I've modified modified Sysbench code to get these changes, and then obtained the following results:
Async I/O : O_DIRECT + O_SYNC
Wrnd "async"+"direct"+O_SYNC with 4K block size:
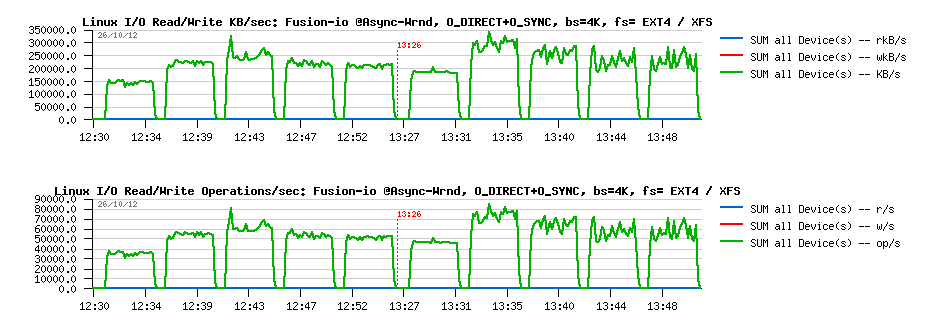
Observations :
- EXT4 performance become lower.. - 25% a cost for O_SYNC, hmm..
- while XFS surprisingly become more stable and don't have a huge drop observed before..
- as well, XFS is out performing EXT4 here, while we may still expect some better stability in results..
Wrnd "async"+"direct"+O_SYNC with 16K block size:
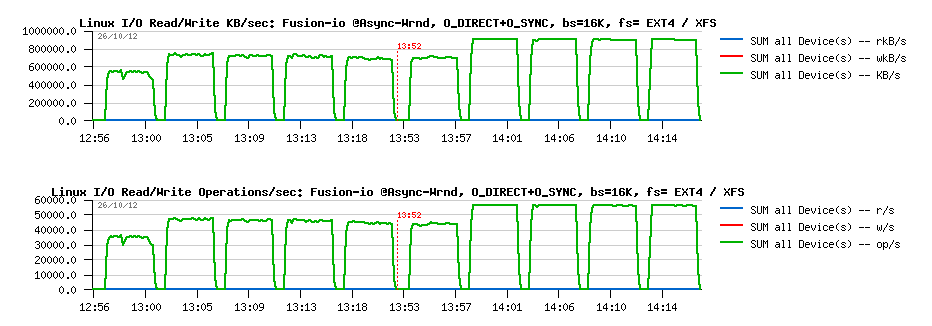
Observations :
- while with 16K block size, both filesystems showing rock stable performance levels
- but XFS is doing better here (over 15% better performance), and reaching its max performance without O_SYNC
I'm pretty curious what kind of changes are going within XFS code path when O_SYNC is used in AIO and why it "fixed" initially observed drops.. But seems to me for security reasons O_DIRECT should be used along with O_SYNC within InnoDB (and looking in the source code, seems it's not yet the case, or we should add something like O_DIRECT_SYNC for users who are willing to be more safe with Linux writes, similar to O_DIRECT_NO_FSYNC introduced in MySQL 5.6 for users who are not willing to enforce writes with additional fsync() calls)..
And at the end, specially for Mark Callaghan, a short graph with results on the same tests with 16K block size, but while the filesystem space is filled up to 80% (850GB from the whole 1TB space in Fusion-io flash card):
Wrnd AIO with 16K block size while 80% of space is filled :

So, there is some regression on every test, indeed.. - but maybe not as big as we should maybe afraid. I've also tested the same with TRIM mount option, but did not get better. But well, to see these 10% regression we should yet see if MySQL/InnoDB will be able to reach these performance levels first ;-))
Time to a pure MySQL/InnoDB heavy RW test now..
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..