« dim_STAT: version 8.3 was updated! | Main | Performance Trainings & Conferences in Kiev »
Wednesday, 09 September, 2009
MySQL Performance: I/O Optimization & InnoDB
After my previous post about InnoDB Doublewrite Buffer impact I've received several feedbacks where people are claiming to see an important performance degradation when they enabling doublewrite... Discussing with them about their wokloads I've tried to reproduce a similar activity with dbSTRESS tool. And finally I was happy (or unhappy - all depends on the side :-))
- Happy because I was able to reproduce the problem :-)
- And unhappy because I've got 30% performance degradation by activating doublewrite buffer!
And now I'll tell you a story how to fix it :-))
Sorry, it'll be little bit long (but it was hard to make it shorter :-))
First
of all let's get a look on the I/O activity and possible solutions to
make it running more optimally...
I/O Requests
Generally we may classify I/O requests by:
- I/O operation: Read or Write
- I/O nature: Sequential or Random
- I/O mode: Buffered or Synced (opened with O_SYNC / D_SYNC or followed by fsync()/fdatasync())
- etc..
And each case has its own solution:
Sequential Write (SW) :
- if your goal is throughput - main rule is to use big I/O blocks (or group several small writes into a big one - may be done by application /filesystem /storage) - latency will be less important here, so even with a simple disk array you still may obtain a very decent performance
- if your goal is operations/sec - use the smallest possible I/O blocks and having a write cache on your storage will help even more (latency will have a big role here and usually it's the only way to have a write response time less than 0.1ms)
-
in any cases having write cache on your storage box will help a lot
(specially if you also have a smart controller chip which may group
and execute several writes in parallel, etc.)
Sequential Read (SR) :
- if your goal is throughput - use bigger I/O blocks
-
in any case to speed-up your SR activity you'll need a kind of
"prefetch" available on your I/O subsystem - it means that next blocks
will be read ahead and placed in buffer even before application
requests them (it may be done by application itself, by filesystem, as
well by storage box)
Random Write (RW) :
- if your goal is throughput - something wrong with your application design :-))
- using smaller I/O blocks giving better performance
- grouping when it possible several writes into a single one helps too
-
having write cache on the storage box helps a lot - it may delay a
real write to disk operation, group and transform several incoming I/O
requests into fewer operations, as well process several writes in
parallel (depending to controller), etc.
Random Read (RR) :
- this is the worse case because in most of cases you really need to read a data block , means 5ms penalty!
- prefetch is not possible here due a random nature of I/O operations..
- so the only way you have to speed-up RR requests is to keep them caches as much as possible !
- in many cases there is no way to cache all needed data, so 5ms penalty in this case is inevitable...
- RR latency may be greatly reducing by using SSD arrays, but it's still remain very costly (but cheaper then RAM :-))
As you may see, the Random Read case is the most problematic and should be avoided whenever possible.
Time to time I'm giving Performance Trainings to Sun engineers as well to Sun customers and partners, and I give them an example of RR impact observed during one of customers benchmarks:
- imagine you have an I/O subsystem giving you 30.000 random writes/sec
- how much you may estimate a performance drop on I/O operations/sec if %5 of your writes will now become random reads?...
What do you think?..
When I'm saying what I've observed was x3 times (!) worse (only 10.000 I/O op/sec) - it's hard to believe.. However it's easy to count:
- due excellent work of controller + write cache pair a random write operation was executed within 0.1ms
- so 100 I/O operations (writes) were executed within 100 x 0.1 = 10ms
- now 5 of them become random reads, and each RR costing ~5ms...
-
100 I/O operations will take now: 5 x 5 + 95 x 0.1 = 34.5ms
Now, let's come back to the issue with doublewrite buffer...
Doublewrite Buffer
So, what may go wrong when doublewrite buffer was activated?..
Workload described in my previous post was prepared mainly to test MySQL code scalability - it avoiding to be much depending on I/O slowness and sized enough to keep a whole data workset cached (and again there are some other issues, but I'll investigate them another day). What's important here - after some time (once data are well sitting in cache) there is no more I/O read requests involved by database!
So what's the I/O activity during this workload:
- there are redo log writes - SW nature, which are very well cached by my storage box which give me 0.1ms service time per write operation
- there are buffer flush list writes - RW nature, but even having configured 16 write threads for InnoDB I never getting more than 2 write operations on the same time (seems to me lock contentions are still quite hot inside of InnoDB) - so my storage box performs pretty well here keepping reasonable service time and writes/sec level
- database performance keeps stable ~11.000 TPS
What's changing once I've enabled a doublewrite?
- same amount of pages flushing from the buffer pool will be also written in parallel into doublewrite buffer
- doublewrite buffer is written to disk sequentially(!) - which means near 0.1ms in my case and should go much more faster comparing to buffer flush writes which are random
- so fast sequential writes going in background of random writes should not decrease performance too much
-
and it's exactly what I've observed! :-))
Testing more aggressive workload
And now - I'm changing the workload conditions. I'm increasing the working set limits in way that clients accessing more wide object references and finally only 10% of data (in better case) may be kept in the buffer pool (even it's quite big). The workload become more close to realistic and more I/O-bound - it's probably more common case for production environment :-) It'll not help to understand scalability issues anymore, but will help to understand InnoDB I/O activity! :-))
So well, what is changed?..
- Database is starting with an empty buffer pool and should really read hard to get some data cached
- The starting performance level is ~1500 TPS now, but it's growing with time as anyway the probability to find data in cache is growing from 0% to 10% anyway :-))
- Random Read remain the main I/O activity during whole test (and the main bottleneck as well)
- Once there is no more free pages in the buffer pool performance is not increasing anymore, but keeping stable...
- Final performance level is around of 3500 TPS (whole test duration is one hour)
- So due RR impact workload is running x3 times slower - which is not surprising...
And if we replay the same test with doublewrite enabled?..
- Due doublewrite I/O activity is more high in volume - but that is as expected :-)
- But performance level reaching only 2500 TPS - this was not expected.. At least I did not expect :-)) I expected to see the same TPS numbers! :-))
So, what's going wrong?..
Looking more in details..
- We may see that workload is already I/O-bound on random reads
- There are random reads! - means you may estimate 5ms cost per I/O operation
- And now between these 5ms reads we're trying to insert our double writes... ;-)
- And even writes are fast, but they are entering in concurrency with RR on storage box controller
- And as I said before - RR data should be really read from disk which is increasing overall latency, and our double writes become not as fast as expected which is creating additional penalty on performance
Any way to fix it?..
My workaround to fix it:
- Initially during all my tests I've always separated InnoDB datafiles (/DATA) from redo logs (/LOG) to the different storage volumes (if not different controllers, but at least different disks) - I've made it for all reasons I've explained before (to avoid RR/RW of data pages add any latency to redo log sequential writes)
- As well I'm using a file per table for InnoDB to split file access (POSIX standard imposing for filesystems to accept only one write operation at any given time for any given file - so it's not really a good idea to keep all InnoDB tables within a single datafile ;-))
- Now - when we activated a doublewrite: where are double writes are going?.. - they are all going into the system datafile!!
- And when is system datafile is placed?.. - right, it's created within the same /DATA filesystem ;-)
-
So, what if we move it now to the /LOG filesystem and instead to mix
it with RR pages will just add its sequential write activity to the
redo log writes? - as storage write cache performed really well for SR
operations until now, it should not be a problem ;-)
$ mv /DATA/ibdata1 /LOG $ ln -s /LOG/ibdata1 /DATA
Observations :
- I/O write volume is really doubled now
- But double writes are not mixed anymore to page I/O activity and not lowered redo log writes either!
-
And you know what? - I've got back my 3500 TPS ! :-))
Going more far..
- The same workaround may help to improve other SW activity involved within InnoDB
- Datafiles are almost accessed in Read and/or Write, random or sequential - we may help here only by using a powerful enough storage
- However doublewrite and binlog are very good candidates for improvement! (and probably some other?)
- Why I call it workaround for the moment? - I prefer to be able to do all this stuff directly from InnoDB - and after that I'll call it solution ;-)
Binlog
And what about binlog?..
- Binlog is using sequential writes
- Each write operation is synced to disk (or not - depends if you're expecting to recover all your data or not :-))
- Binlog files are created and growing dynamically until they reach max_binlog_size
Potential problems:
- By default binlog files will be created within the same directory where your datafiles are ;-)
- Why it's bad?.. - first of all it's bad because if your /DATA storage is crashed you'll be unable to replay your binlogs on your latest backup :-) - and the second reason is the same I/O impact as we saw previously with doublewrite :-)
- Then binlog file is never created ahead...
- And the problem here is that on many filesystems each single write() increasing file size will be transformed to 2(!) physical writes! (one for data and one for ~infrastructure~) - so very easily you may do 2 times more writes on your storage than you should! (unless your filesystem is managing blocks by extents like ZFS, VxFS, QFS, etc..)
- But in any case - why not to create binlogs ahead??? - space may be allocated in background by sequential writing of big blocks - it should be very fast! - then binlog writes will run faster for sure whatever filesystem you're using!
Suggestions
To summarize, here is the current list of my suggestions:
- Have a separated file for doublewrite! - and then place it according a user setting (for ex. use some kind of innodb_doublewrite_file option) - and it'll be a real solution! :-)
- Create binlog files ahead! - and probably add an option how many files should be created ahead (it's much more easier to create a 1GB binlog before it'll be used as there will be no any kind of sync impact!)
- Probably there are also other InnoDB sequential write activities which are also meriting to be placed into the separated file(s) - what do you think?..
Any comments are welcome! :-)
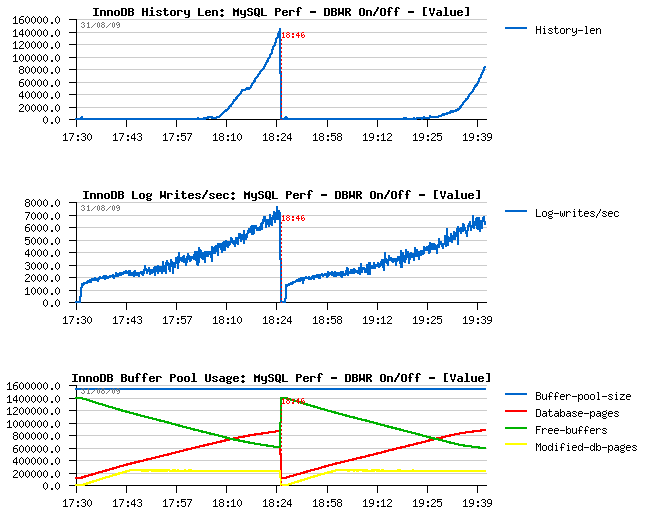
Few Graphs...
Just few graphs at the end comparing InnoDB activity when Doublewrite Buffer is set OFF and then ON.
Few comments :
-
I've increased a buffer pool that time to be not out of free pages
within one hour :-)
-
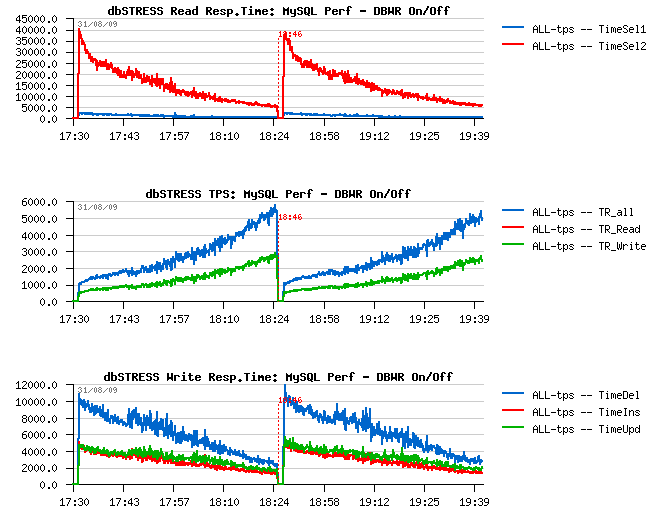
After one hour of activity performance level reached ~5000 TPS
-
Similar performance level is also observed when doublewrite buffer is
ON
-
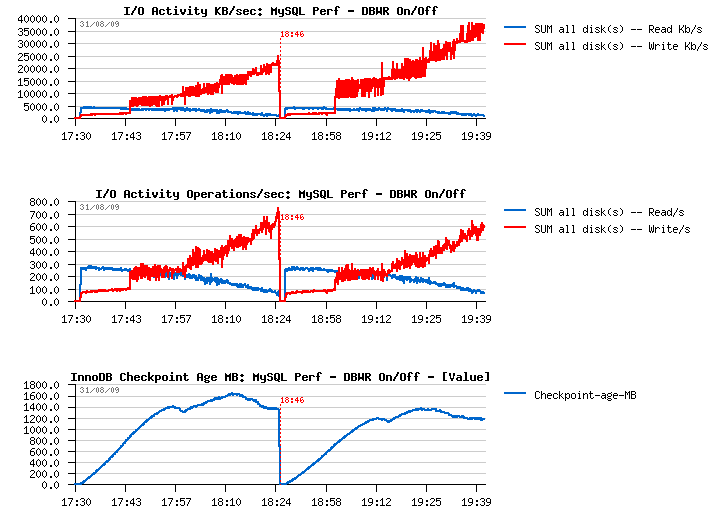
I/O write amount is 2 times higher when doublewrite buffer is
ON, however the I/O write operations are remaining the same!
(so Sarah was right :-))
-
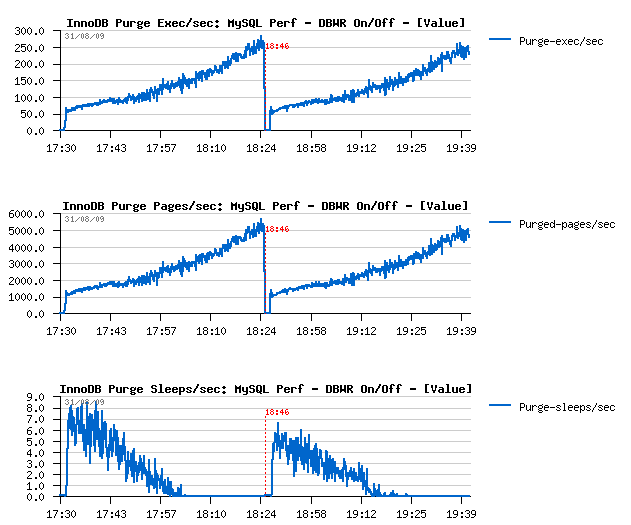
With a growing performance level, purge activity become more and more
important, and finally there is no more sleeps within a purge loop -
so having a separated purge thread is THE MUST! :-) (see here
for more details why)
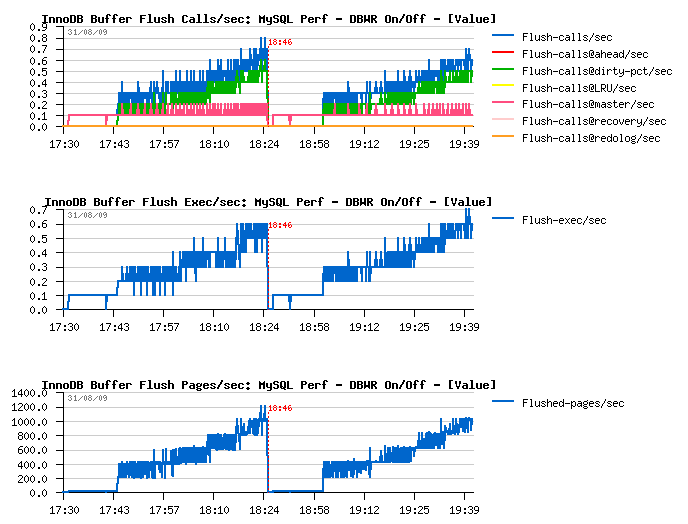
- Current I/O-bound workload performing better if dirty pages are flushed when reaching a dirty pages percentage limit and NOT by adaptive/ahead flushing/checkpoint - Why? - because in this case it involves a single flush batch with a full I/O capacity - and as I/O subsystem is already very hot this batch will be unable to create a burst activity - it'll slowly write pages in background, then max dirty percentage will be reached again and so on.. - what's important it'll call flush batch much more less times then any other of available (ahead) methods - but again, it's only possible if your purge processing is splitted into another thread! :-))
TPS level and Response times
Dirty pages flushing
Purge activity
I/O Activity and Checkpoint Age
InnoDB Buffer Pool, History list length and Log writes/sec
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..