« MySQL Performance Talks during UKOUG Conference in Birmingham (UK) | Main | MySQL Performance: InnoDB double write buffer & redo log size impacts @MySQL 5.5 »
Wednesday, 29 December, 2010
MySQL Performance: Analyzing Percona's TPCC-like Workload on MySQL 5.5
Last week Percona team published the benchmark results comparing beta XtraDB and MySQL 5.5 GA performance on their TPCC-like test workload (http://www.mysqlperformanceblog.com/2010/12/20/mysql-5-5-8-and-percona-server-being-adaptive). The results are very interesting because they are involving many questions about existing implementations of different features within InnoDB and bring new ideas as well. However, what is missing for me in this publication is an analyze of the tested workload and InnoDB issues.. - finally I've got much more questions than answers :-)) and it was pity for me to finish this year with a such "enigma" in my mind ;-)) So, as XtraDB is not ready yet, I was curious at least to get my own look on the Percona's TPCC-like workload and satisfy my curiosity ;-))
The main question not leaving my mind was about observed performance drops from the first graph: http://www.mysqlperformanceblog.com/wp-content/uploads/2010/12/500wRAID.png - it was strange for me to see such holes on the TPM curve specially on MySQL 5.5.8 which looked even on my stress test just fine now.. And, honestly, I'd prefer a slightly lower performance but stable, rather high peaks, but with performance drops.. So, for me there were only two possibilities: we really completely missed something.. or something was wrong with InnoDB tuning used during Percona tests.. - but in both cases you have to dig it in depth.. And nothing better to understand a problem than to dig it yourself.. :-))
{kind=link}
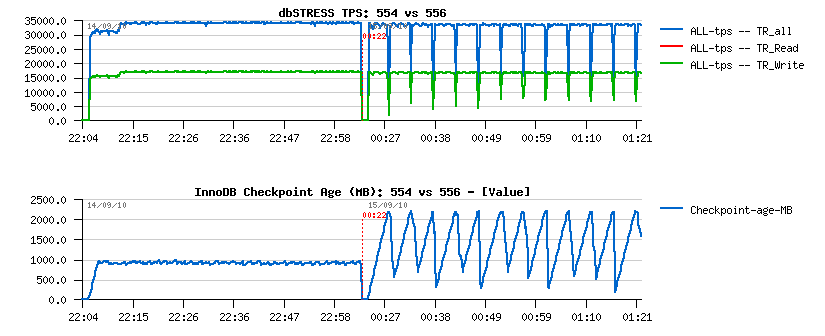
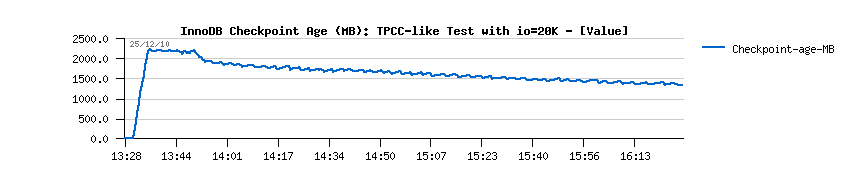
- 5.5.4 is flushing more aggressively and it results in a lower (but stable) Checkpoint Age, but should involve higher I/O writes rate (however it's still keeping stable TPS too)..
- 5.5.6 is way less aggressive in flushing, so Checkpoint Age is not kept under a critical limit which is provoking periodic "furious flushing" and as the result - TPS drops..
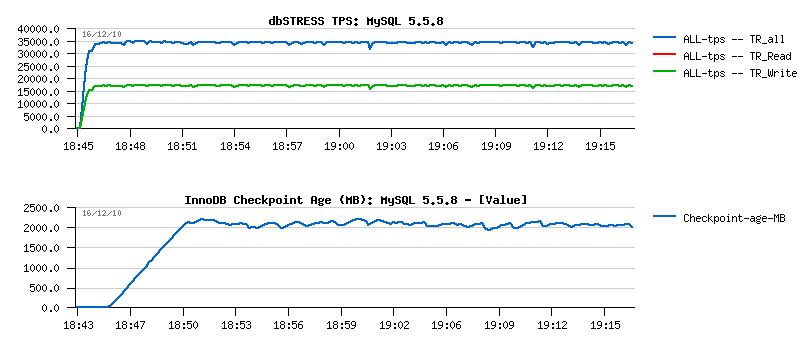
- there is no more TPS drops
- and flushing is just fine: not too much aggressive and not too relaxed either, but just as needed..
-
get
the tpcc-mysql
$ bzr branch https://code.launchpad.net/~percona-dev/perconatools/tpcc-mysql
-
$ cd tpcc-mysql/src; edit Makefile if needed, I've just manually added
values to LIBS and INC to point to my own paths:
LIBS= /apps/mysql558/lib/libmysqlclient.a -lm -lz -lpthread -ldl
INC= -I. -I /apps/mysql558/include/
-
$ make
that will compile you 2 binaries: "tpcc_load" and "tpcc_start"
-
create the tpcc database schema with owner/password = dim/dim:
$ echo "create database tpcc;" | mysql -udim -pdim -h127.0.0.1 -P5400
$ mysql -f -udim -pdim -h127.0.0.1 -P5400 tpcc < create_table.sql
$ mysql -f -udim -pdim -h127.0.0.1 -P5400 tpcc < add_fkey_idx.sql
-
Generate 500 warehouses:
$ ./tpcc_load 127.0.0.1:5400 tpcc dim dim 500
-
Starting a test with 16 users on 500 warehouses for 3 hours:
$ ./tpcc_start 127.0.0.1:5400 tpcc dim dim 500 16 120 10800 > Test_16usr.log
- Server: 32 cores bi-thread Intel box running under Linux, 64GB RAM
- Storage: single Intel SSD disk of 128GB (yes, only one disk, but hope it'll be enough for my test :-)), under EXT4
- Data: 500 warehouses (50GB already, so I hope it'll be enough to reproduce the observed flushing issue.. - anyway, I don't have a place for 1000 warehouses data anyway for the moment..)
- Users: 16 concurrent users expecting to replay the same workload as reported by Percona team..
- Test duration: 3 hours (as data even during 3 hours are growing by 50% there is no really any reason to run a test longer as I'm pretty sure there will some background effects come in the game due a bigger volume of rows in some tables and it'll completely change the test conditions :-)) so even 3 hours within a such test is too much (well, 50% of growing volume is too much to guarantee that the test conditions are remaining the same as on the beginning of the test)..
Initial MySQL configuration settings:
[mysqld] max_connections=2000 key_buffer_size=200M low_priority_updates=1 sort_buffer_size = 2097152 table_open_cache = 8000 # files innodb_file_per_table innodb_log_file_size=1024M innodb_log_files_in_group=3 # buffers innodb_buffer_pool_size=32000M innodb_buffer_pool_instances=16 innodb_additional_mem_pool_size=20M innodb_log_buffer_size=64M # tune innodb_checksums=0 innodb_doublewrite=0 innodb_support_xa=0 innodb_thread_concurrency = 0 innodb_flush_log_at_trx_commit = 2 innodb_max_dirty_pages_pct = 50 # Perf innodb_io_capacity = 2000 innodb_write_io_threads = 16 innodb_read_io_threads = 16 innodb_adaptive_flushing=1 innodb_purge_threads=1
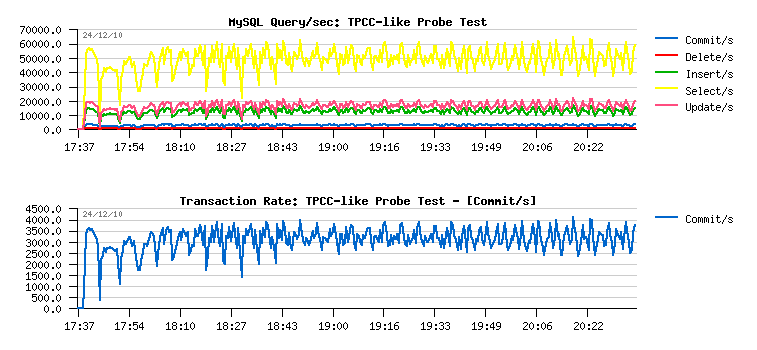
- over 50,000 SELECT/sec
- ~20,000 UPDATE/sec
- ~15,000 INSERT/sec
- small amount of DELETE/sec
- COMMIT/sec may be probably considered as TPS metric as auto-commit seems to be disabled within TPCC-mysql code, so having peaks at 4,000 commit/sec I may suppose the test is running in peak on ~24,000 TPM.. - however at the end of the test tpcc-mysql reported 58713.129 TpmC in the log file :-)) so seems there are other kind of transactions are accounted within TPM too.. - so to be based on the live and real time data I'll align all my next analyzing with COMMIT/sec levels, for ex. the current level is around of 3000 COMMIT/sec. Let's keep it as a base line..
mysql> show global status like '%ahead%'; +---------------------------------------+--------+ | Variable_name | Value | +---------------------------------------+--------+ | Innodb_buffer_pool_read_ahead | 11 | | Innodb_buffer_pool_read_ahead_evicted | 207619 | +---------------------------------------+--------+ 2 rows in set (0.00 sec)
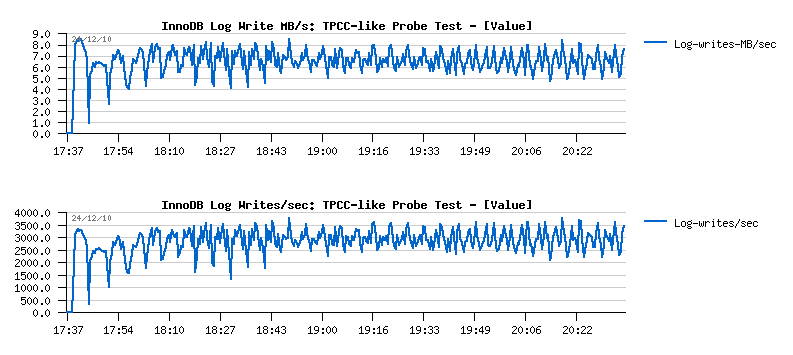
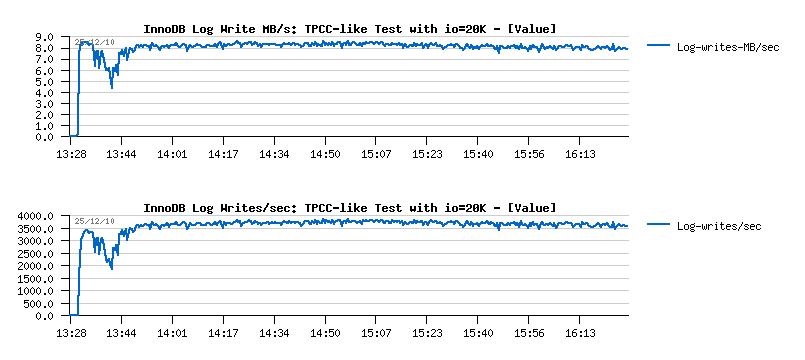
- 3000 log writes/sec resulting in ~7MB/sec writes
- having "innodb_flush_log_at_trx_commit=2" setting will keep all log writes buffered within filesystem cache and then flush them once per second, so filesystem will sequentially write 7MB/sec..
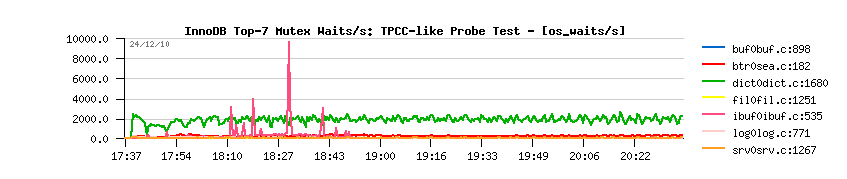
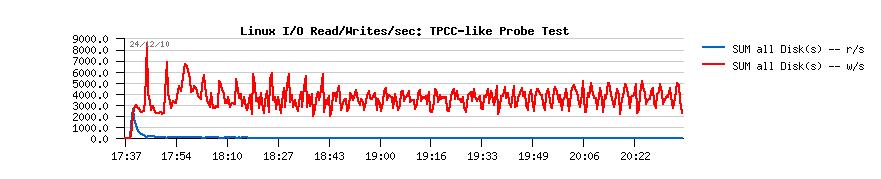
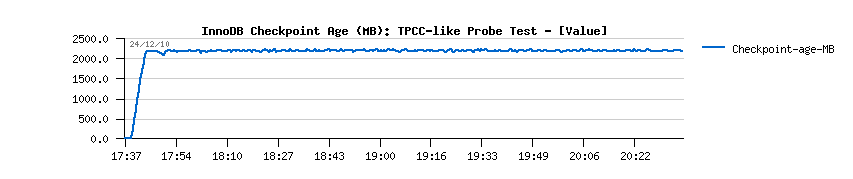
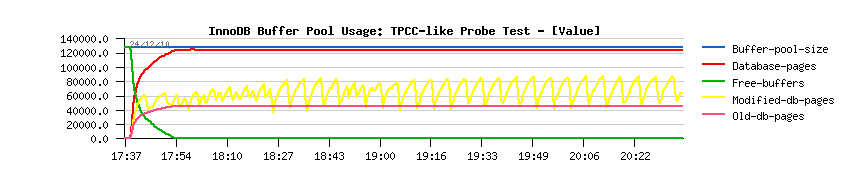
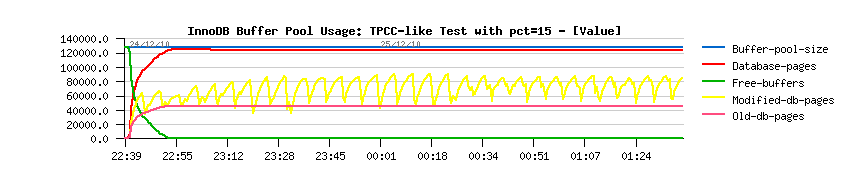
- initially the flushing activity within InnoDB was managed only by the dirty pages percentage setting, and to avoid "furious flushing" user adapted this setting according his/her database activity..
- IO capacity setting came to replace the default hard coded 100 pages value to flush per second - even a single hard disk drive is able to do more than 100 writes/sec today, and InnoDB now is trying to flush 100% of IO capacity when the dirty pages percentage limit was reached..
- however, it may still not protect you from a furious flushing - the number of records within REDO logs are not directly depending on the number of the dirty pages you're having within you Buffer Pool, so your dirty pages may still be under the required limit, while there may be no more free space within REDO logs.. - so you'll need to flush your dirty pages as soon as possible to make a room within your REDO logs and be able to continue transactional activity.. And to solve this issue, Adaptive Flushing is coming in the game.
- XtraDB is ignoring IO capacity setting and simply writes as much pages as it estimated to flush (and was the first to have this "adaptive" feature (Adaptive Checkpoint))
- while InnoDB is respecting IO capacity limit, and will not out-pass this limit even if it estimated to flush more..
- personally, I prefer to respect IO capacity limit because it gives you a way to limit I/O writes from a given MySQL instance (and if you're running several MySQL instances on the same server it'll help you to better share resources, and as well if you're using a shared storage, etc.)
- then if you're not liking any IO limitations - simply set IO capacity way higher, for ex. 100000 and you're done! ;-))
- enable adaptive flushing
- adjust dirty pages percentage limit
- adjust IO capacity
-
innodb_max_dirty_pages_pct=15
-
innodb_io_capacity=20000
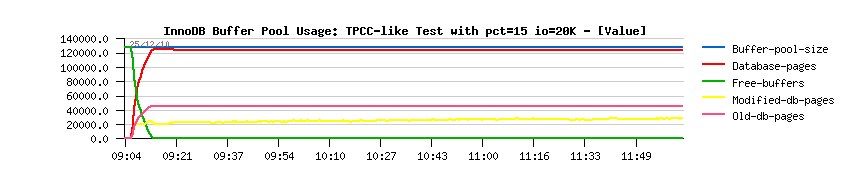
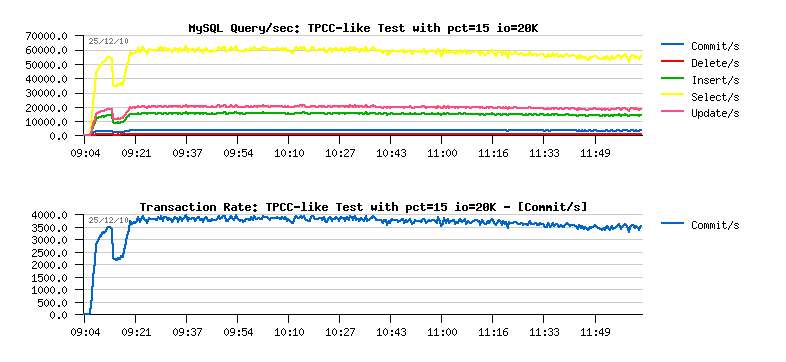
- first of all there are no more periodic drops we observed before!! (except the one on the beginning of the test)
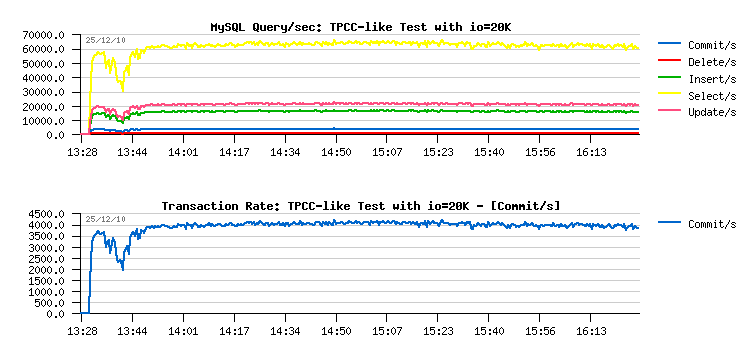
- SELECT/sec out-passed 60,000/sec !!
- and COMMIT/sec is near 4,000/sec, but over a time slowly decreased to 3,500/sec..
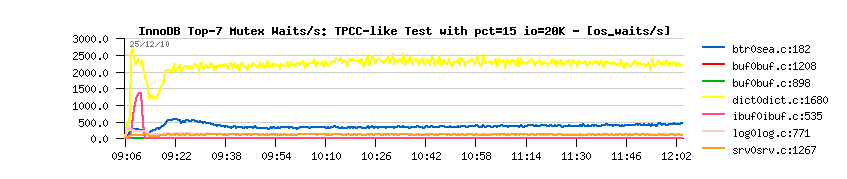
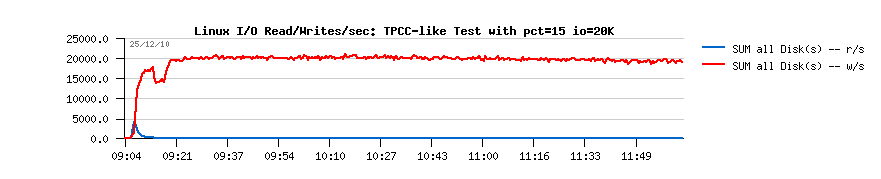
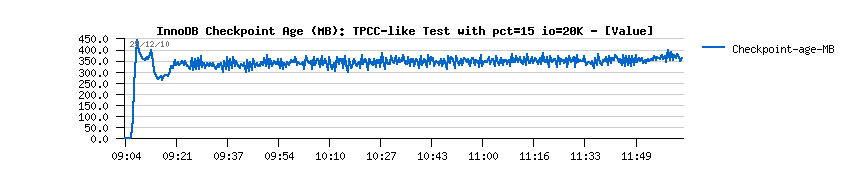
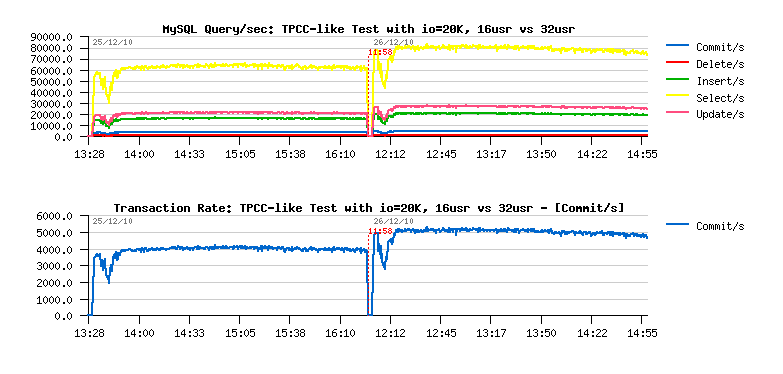
- over 65,000 SELECT/sec !!
- over 4,000 COMMIT/sec !!
- still the same drop on the start, but you know why ;-))
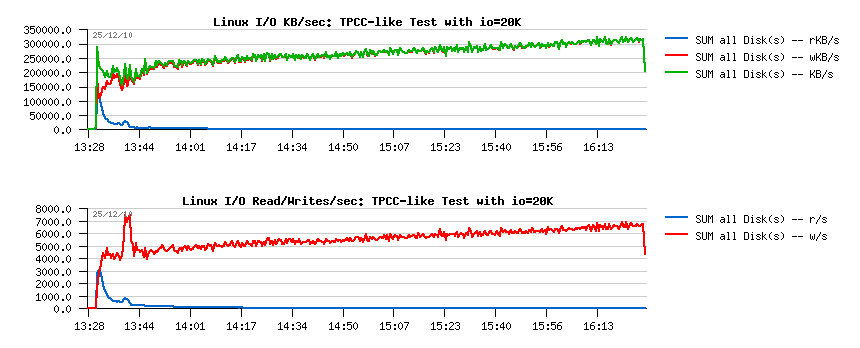
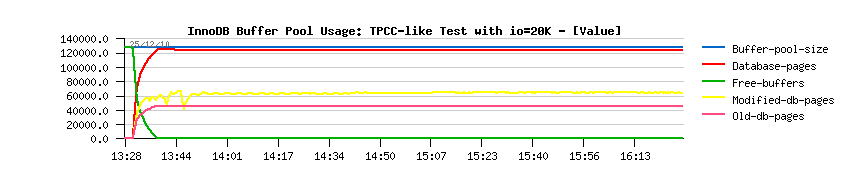
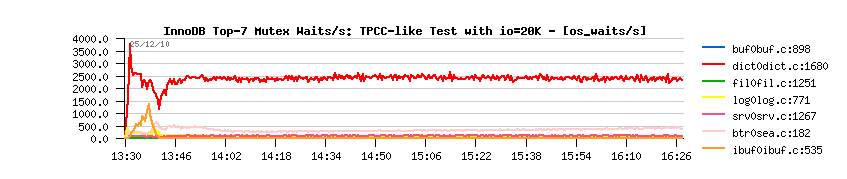
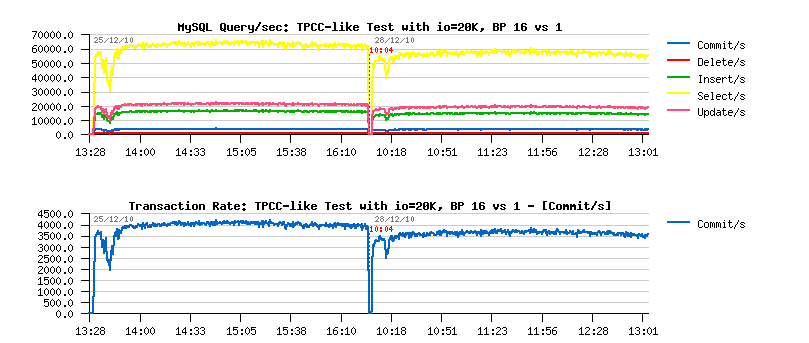
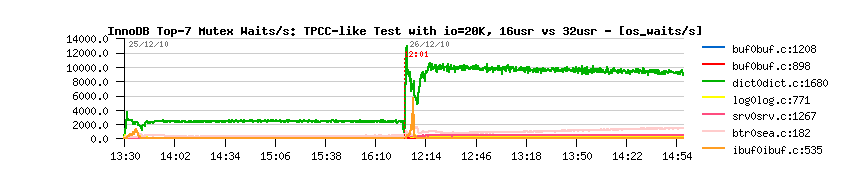
- performance is still stable as before!..
- and at least %25 performance improvement!..
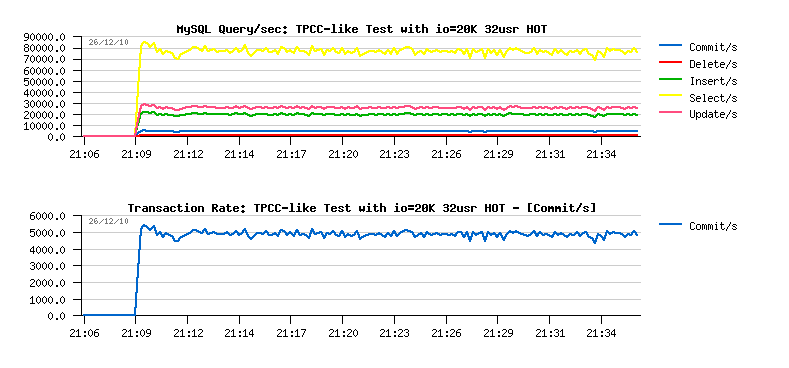
- initial 16 users test: 58713.129 TpmC
- final 16 users test: 74013.625 TpmC
- final 32 users test: 93284.812 TpmC
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..