« MySQL Performance: 5.6-labs is opening a new era.. | Main | MySQL Performance: 5.5 and 5.6-labs @TPCC-like »
Friday, 13 April, 2012
MySQL Performance: Improved Adaptive Flushing in 5.6-labs
I'd start this blog post with "I've had a dream".. ;-))
Seriously,
it was my dream from a long time that "official" MySQL code comes with a
more improved Adaptive Flushing solution in InnoDB.. - and now, with
5.6-labs release, this dream becomes a reality ;-))
The story
with Adaptive Flushing is so long.. Started by Yasufumi after his
brilliant analyze of the flushing problem in InnoDB, then integrated in
XtraDB as Adaptive Checkpoint, then came in alternative way as Adaptive
Flushing in "official" InnoDB code, then yet more improved within
Percona Server, etc. etc. etc.. (my last
post about was one year ago, and it was already a call to action
rather a general discussion about performance improvements ;-))
However,
it took a time to get similar improvement within an "official" InnoDB
code, but not because people are lazy or not open to changes, but just
because the already implemented solution within InnoDB was simply "good
enough" in many cases ;-)) specially with appearing of the page_cleaner
thread in 5.6.. The only weak point it has is that it's unable to keep
load spikes (but in this point no one of existing solutions is good,
even in XtraDB), and it may take a long time before to "adapt" to a
given workload..
Let's get a look on the following graph: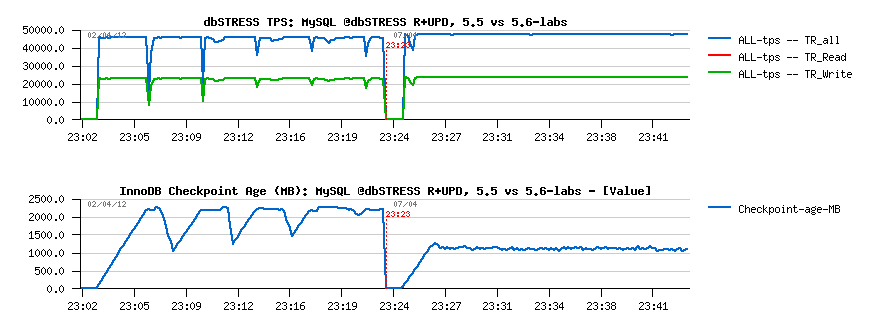
Explanations:
- this a light dbSTRESS RW workload with 32 concurrent user sessions
- MySQL 5.5 and 5.6 are both having a similar drops in TPS level (left part of graph)
- these drops are due Checkpoint Age reaching max REDO log space
- so urgent burst flushing (furious flushing) is involved to create a room of free space within REDO, otherwise the whole transactional processing is remaining frozen..
- however, over a time such drops are less and less important, so some users may probably even live with it..
- but on the right part of the graph you may see 5.6-labs solution in action, and there is no more any drops at all (except the initial one which is related to adaptive hash index initialization)
- as well, 5.6-labs is keeping a quite significant marge in Checkpoint Age in case there will some spikes happen in the load with increased activity (where 5.5 will almost have TPS drops every time..)
To be sure we're not reinventing the wheel, we even ported most interesting solutions to the 5.6 prototype trunk, and I've tested all of them on the more hard RW workload:
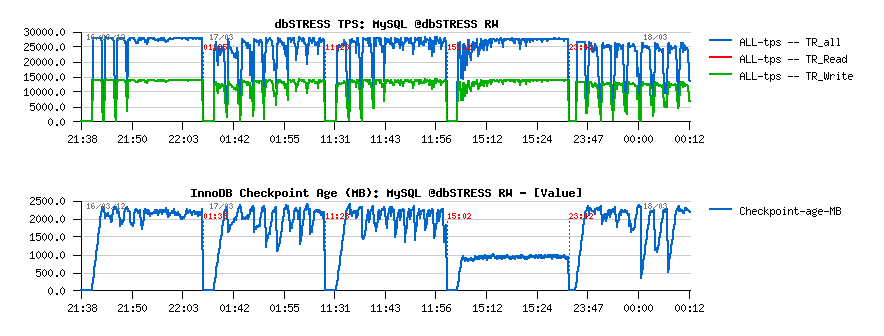
From the left to right:
- 5.6-native
- 5.6 + "estimate" from Percona
- 5.6 + "keep avg" from Percona
- 5.6-labs
- Percona 5.5 (this one I've tested just to be sure nothing was wrong with a logic in a ported code)
As you may see directly from these graphs that our solution (implemented now in 5.6-labs) looked more attractive from the beginning.. And I'm very happy to be able to contribute to it, as several of my previously expressed ideas were accepted to be a part of this solution too ;-))
So, what was changed in the improved Adaptive Flushing (AF) in MySQL 5.6-labs:
- first of all the logic is moved to the REDO log space occupancy rather tracking estimation of pages to flush as before
- more REDO space is filled, and more aggressively becomes InnoDB is flushing
- less REDO is filled - more relaxed is flushing..
- the relation between REDO occupancy and flushing power level is progressive and non-linear..
- all the time we're also considering the average REDO filling speed and average amount of flushed pages
- these averages are helping to guide the AF decisions to better adapt dirty pages flushing according database activity..
- then only point which is remaining yet open is a case when pages flushing is unable to follow REDO writes simply because of weak I/O layer.. - we already have a solution here too, but it's not yet part of 5.6-labs ;-)
From the user/DBA point of view the AF configuration as looking as simple as following:
- the IO capacity setting is still remaining (and used for most maintenance tasks within InnoDB - you should consider it now as kind of AVG I/O write activity you're expecting to see from your database server in general, specially useful if your MySQL server is running with many other applications on the same machine (or other MySQL instances as well))..
- the "Max" IO capacity is introduced to say how high InnoDB is allowed to go in flushing to be able to follow REDO log activity
- the Low Watermark is introduced to say since what percentage of REDO log space filling the AF processing should be activated - depending on your workload it may vary.. (default is 10%)
- all configuration variables are dynamic and can be changed at any moment ;-)
So, once you've set your limits - InnoDB then will try to do the best with what it has :-)
And all AF internals are available for monitoring via METRICS table:
- buffer_flush_adaptive_total_pages -- getting delta of this value divided by the time interval giving you the current speed of pages flushing due AF
- buffer_flush_avg_page_rate -- the average pages flushing rate seen and considered within AF, and if everything is going well with your I/O level, this value should less or more follow the previous one ;-)
- buffer_flush_n_to_flush_requested -- the amount of pages requested for flushing by AF (and which may be quite different from both previous counters because the avg REDO filling speed is also coming in the game, and may limit a real flushing by pages age)..
- buffer_flush_lsn_avg_rate -- LSN avg rate seen by AF (corresponding to the REDO logs feeling speed and used as age limitation barrier when flushing is involved -- so we may then flush as many pages as requested or less, because of this age rate).. - when on the I/O level everything is going well, this value should less or more follow your REDO MB/sec write speed, and grow in case of lagging to increase the current age barrier for flushing..
There are also some other counters, but let's skip them to keep stuff simple ;-)
Now, replaying the same RW workload presented before on MySQL 5.6-labs with:
- innodb_io_capacity = 2000
- innodb_max_io_capacity = 4000
will give us the following:
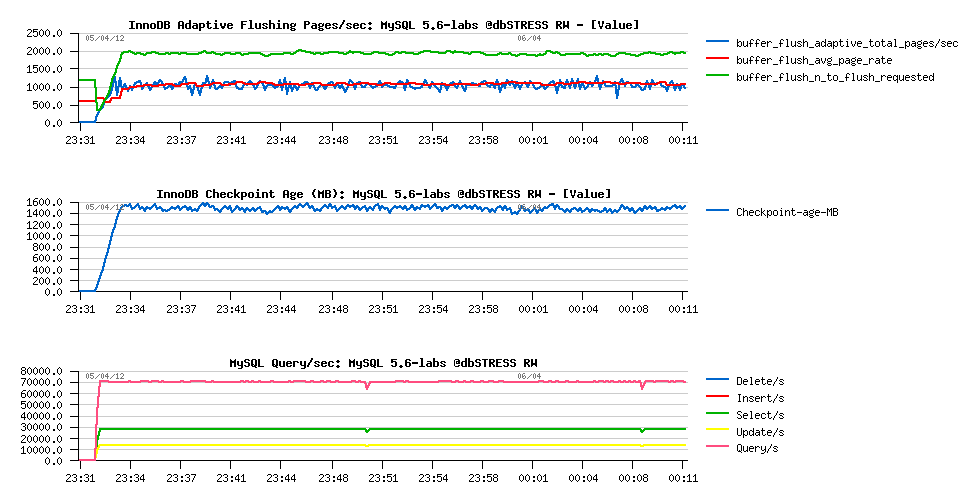
So,
- AF is requesting to flush 2000 pages according its estimation
- but in reality flushing 1000 pages/sec is quite enough to keep Checkpoint Age on a reasonable level
- 70K QPS is reached..
But what will be changed since there will be some activity spikes?..
I'll mix now this workload with Sysbench OLTP_RW - additional 16/32 users sessions will come and leave the database activity with their RW transactions:
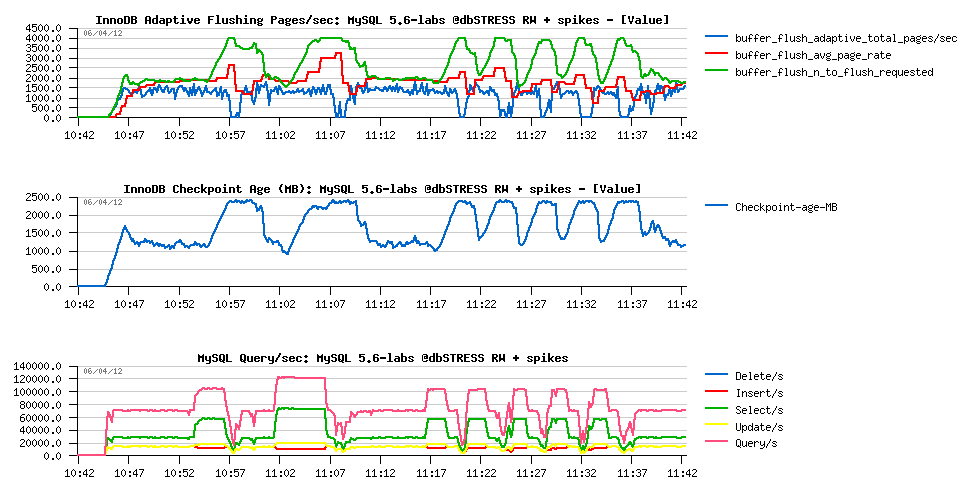
Observations:
- Checkpoint Age is jumping up during spikes in activity..
- within a current I/O configuration InnoDB is unable to flush faster than 1500 pages/sec..
- which is resulting in QPS drops during these spikes..
-
What can we do to help here?..
- we may improve the I/O level performance (sure will help! ;-))
- or expect that is the spikes are not too long in time, with a bigger REDO logs there will be more room to resist to them..
So, now replaying the same test case, but now with using 8GB REDO logs total space:
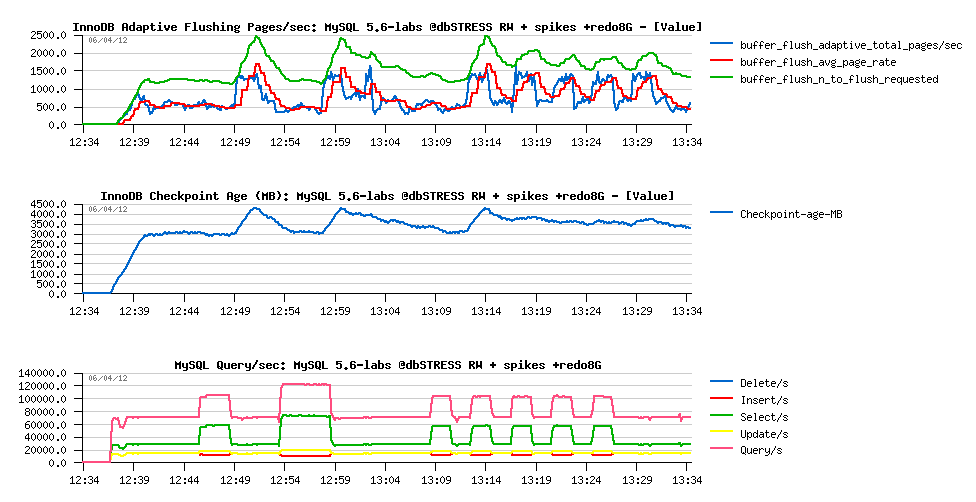
Observations:
- having a bigger REDO space automatically reduced the flushing rate during "quiet periods" (from 1500 to 500 pages/sec)
- and we're reaching 1500 pages/sec flushing only during spikes now..
- the marge on the REDO log space is big enough to keep Checkpoint Ages jumps under critical level
- which is resulting in a total absence of QPS drops ;-)
Or the same workload on a served with less powerful CPUs, but more powerful storage level:
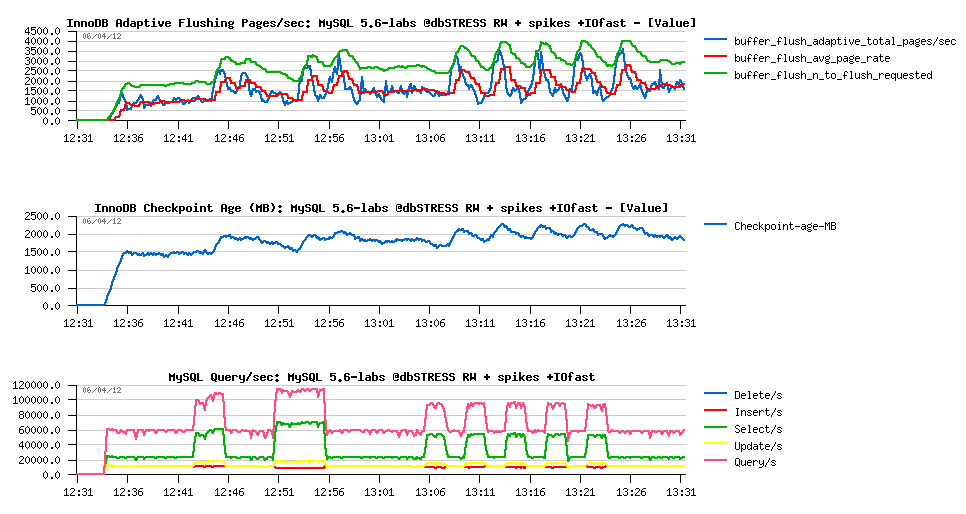
Observations:
- QPS level is lower due lower CPU speed
- but dirty pages flushing level is way faster when requested, easily reaching 3000 pages/sec
- so we're not observing any QPS drops on activity spikes as Checkpoint Ages levels were never critical..
Looking on these results we may be only happy, because none of ones was possible to achieve with MySQL 5.5 and previously in 5.6 (both will keep Checkpoint Age too close to the critical limit, so any activity spike will bring a TPS drop)..
After these "complex" tests, let's get a look on a "simple" Sysbench OLTP_RW between 5.5 and 5.6-labs:
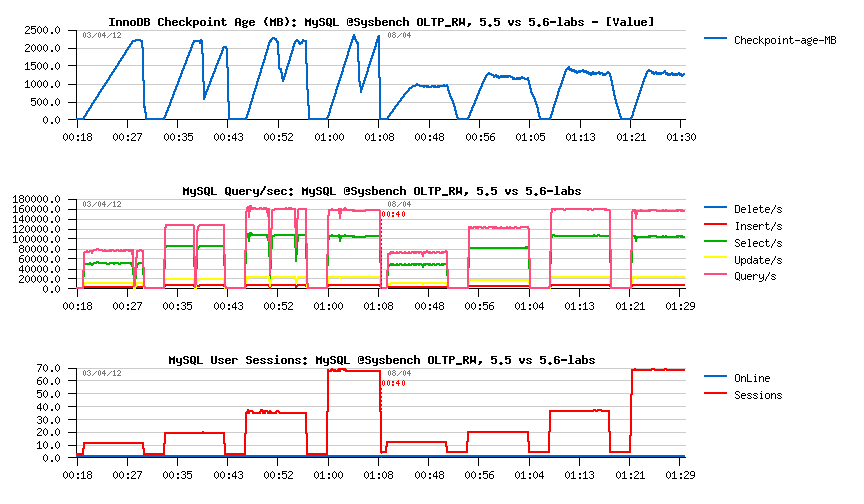
As you can see, as soon as you have to flush due reaching critical Checkpoint Age levels - as soon you'll have TPS drops too.. It's what we're observing in 5.5 and before in 5.6 - but I hope time is changed since 5.6-labs ;-))
The solution is not yet final, but at least very promising and pretty easy to tune ;-) but more testing will give us more ideas about how the final code should look like.. - so don't hesitate to test it on your own systems and your own workloads!! ;-))
As the final word, I'd like to thank Inaam from InnoDB team for his patience in implementation and adoption of all the ideas we have around into a single and truly integrated within InnoDB code solution!.. Kudos Inaam! :-))
I'd say, and you may just trust me, since 5.6-labs benchmarking MySQL will become much more interesting! ;-))
Rgds,
-Dimitri
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..