« MySQL Performance: 5.6 Notes, part 4 - Fixing Purge issue.. | Main | MySQL Performance: 5.6.2 and Performance Schema »
Tuesday, 12 April, 2011
MySQL Performance: 5.6 Notes, part 5 - Fixing Adaptive Flushing..
This is the 5th part of the MySQL 5.6 Performance Notes started from here.
Adaptive Flushing implementation is maybe one of the hottest topics discussed around MySQL 5.5 and InnoDB performance (and even way before 5.5) - if you will "google" for "furious flushing" you'll find many interesting things.. But well, the problem is still here for the moment, in 5.6 too, even if 5.6 is looking much more better facing it.. But well, it'll be great to fix it and then forget about.. - I think it's a time now, no?.. :-))
Fixing Adaptive Flushing in MySQL 5.6.2
Honestly, it's a pity to see Adaptive Flushing to be not so "adaptive" within MySQL 5.5 and 5.6 for the moment.. I very hope this situation will change very soon ;-)) And as there will be many versions of the "fix" to consider, here is mine..
First of all, let me summarize all previous discussions I've already presented in the past in various blog posts and benchmark reports, and try to finalize it now into a "something".. ;-)) I don't think there is something new in understanding of the problem, but a short summary will help to be aligned with a proposed solution :-))
What is the real problem with all this flushing issues?.. - The true problem is a presence of "furious flushing" when InnoDB is starting to flush too much at some moments and independently to the load that the whole "user land" work is freezing.. Then, what is the real source of the problem with a "furious flushing"?.. - the problem is coming from the state when InnoDB is realizing that it's short in free space within REDO logs and it needs to flush the oldest pages as soon as possible to make a room of free space.. - there is a very good overview with nice pictures about this situation presented by Vadim in his recent blog post (http://www.mysqlperformanceblog.com/2011/04/04/innodb-flushing-theory-and-solutions/) - so to summarize in few words:
- The goal is to "never leave Checkpoint Age to out-pass Async limit" within InnoDB !..
Now, how can we achieve it?.. - and there are 2 self-barriers:
Barrier #1: we have to flush fast enough to keep oldest page modification within a room of Checkpoint Age before Async..
Barrier #2: I may imagine the situation that we're unable to flush as fast as we're writing REDO logs due storage limitations (HW problem) - in this case we have to slow down REDO writes too keep equilibrium.. - Personally I never meet such a situation, but looks like we can now track it with P_S and at least point on when it happens, but then should keep in mind and have a solution to prevent out-passing Async limit..
There is still another issue which may also involve an intensive flushing following by freeze of user sessions - it's LRU flushing (when you have to flush oldest dirty pages to make a room of free space within a Buffer Pool), but with introducing on the Page Scanner thread since 5.6 this problem should be gone.. (need yet to be tested)..
Now all about #1 Barrier..
When we're flushing?..
- Adaptive flushing: should be "adaptive", so an average flushing, not too hard, not too slow, just as needed..
- Dirty pages max percentage: 100% IO capacity, may be hard..
- Async (short in free REDO logs space): very aggressive, but non blocking..
- Sync (very short in free REDO logs space): very aggressive, blocking all..
It's clear that Sync and Async flushing are not our friends :-))
For a "normal tuning" we have only Dirty pages percentage and Adaptive flushing to play with.
Dirty pages: globally it's not a problem to have many dirty pages within InnoDB Buffer Pool - all changes are secured by REDO log records, and there is no really need to urge to flush them until we're not too short with free space in REDO logs.. But with 32GB or 64GB Buffer Pools we may keep way more dirty pages than corresponding records can be kept within 4GB REDO log space.. So, with a big Buffer Pool sizes we probably may never see max dirty pages level hitting its max as the flushing may be involved way ahead via Async or Sync flushing (due REDO space).. - and we get "furious flushing"..
Then it's still possible to set the Max Dirty pages percentage too low, but it'll be hard to find an optimal value for it as the load may vary, and flushing may become more aggressive in other conditions..
And it's still possible to increase the max 4GB limit for REDO logs and it'll help - as the Async limit will be more far, and then reaching Max Dirty pages percentage we'll flush for sure! - however this flushing may be quite aggressive as it'll involve a 100% IO capacity burst.. - but still better than "furious flushing" :-))
Adaptive Flushing, however, should play the best role here as an option, but what is a difficulty to implement?..
First of all, it's hard to estimate a number of dirty pages corresponding to N records in REDO log.. - for ex. for 2000 REDO records there may be 2000 modified pages or one single page with 2000 in place modifications, or 20 pages with 100 modified rows in each :-))
When your modifications are widely spread over pages, there will be maybe even no need to have too big REDO logs to keep their changes as as soon as you you'll read new pages into your Buffer Pool you'll hit the Max Dirty pages percentage or will be short in free pages within your Buffer Pool and will hit LRU flushing - and in both cases your Checkpoint Age will be still be far away from the Async limit and "furious flushing" will never happen (and as LRU flushing is involved by Pages Scanner since 5.6 it'll not involve any freeze on user threads anymore)..
So, the real problem is coming only in cases when the changes are "focused" on some amount of pages and the dirty pages number remaining still low, while the Checkpoint Age may grow fast.. - having a bigger than 4GB REDO log space will help here as it'll avoid to flush pages before the "focus" did not move to other pages (and then previously modified pages will be flushed only once instead of being flushed per each modification for ex.).. However if the "focus" is not moving, we'll still reach the Async limit even with a bigger than 4GB REDO logs - each space has its limits :-))
To summarize:
- Max Dirty pages percentage will guarantee ahead flushing if modifications are not "focused"
- Over 4GB REDO logs will reduce flushing operations of "focused" modification
- Adaptive flushing should keep flushing active in cases where Max Dirty pages percentage will not work..
So, what is wrong with Adaptive Flushing?..
As said before, it's hard to "estimate" the correspondence between dirty pages and REDO records.. - and it's what we're trying to do (and Percona in some cases).. And finally why try to "estimate" something which is completely random??..
I think that instead of estimation we should simply "adapt" our flushing speed according "observations" on the Checkpoint Age and Max Dirty pages percentage:
Avoid a 100% IO capacity burst flushing due Max Dirty pages percentage:
- when Dirty pages percentage is reaching 1/4 of Max we may already involve a 5% IO capacity flush
- for 1/2 of Max => 25% of IO capacity
- and so on..
Then on Checkpoint Age:
- let's keep the 1/2 before Async limit as a Goal (G-point)
- also we have to track the LSN speed of REDO writes (accounted as AVG over current and past changes)
- then up to G-point we may adapt flushing progressively from 1 to 100% of IO capacity
- so, on G-point we're flushing 100% IO capacity
- then on each flush request we have to precise the max LSN (instead of "max integer" currently) to flush just as needed according the AVG LSN speed..
- then since Checkpoint Age is out-passing G-point, the flushing speed is increased with acceleration, say: flushing= IO_capacity + IO_capacity * P * P / 10 (where P is a percentage of out-passing G-point, so if we'll reach Async limit it'll be with 11x times of IO capacity)
- then if on 70% of out-passing of G-point we still observing Checkpoint Age growing, then we may suppose the storage subsystem is unable to keep required write load and it's time to slow down REDO log writes to avoid Async flushing... (Barrier #2)
Why G-point is on the half-path to the Async limit?.. - I simply think about every DBA and Performance Consultants who will try to tune MySQL in production according their observations.. - such a tuning should be "simple" and predictable and not based on some kind of "magic calculation" which in some cases working, in some cases not..
So, what it'll be such a tuning like?..
- IO capacity setting is involved within many "maintenance" tasks such as light background flushing when activity is low, etc..
- REDO log size 4GB limitation will be gone since the next 5.6 version (code is already in the public trunk)..
- then you simply know that once Checkpoint Age is reaching the half of the Async limit your database is already involving a flushing on 100% IO capacity speed..
-
and then you have 2 options:
- you're monitoring yourself your database and if Checkpoint Age remaining always low you may simply decrease the IO capacity to reduce flushing (IO capacity is a dynamic option) NOTE: as we'll also track LSN speed over time within Adaptive Flushing code, in any case it will not flush a bigger amount of pages than the age shift corresponding to the LSN speed..
- or use an "auto" option, and leave Adaptive Flushing to auto-adaptively decrease its "own" IO capacity to keep Checkpoint on G-point, or increase it up to the "configured" IO capacity if the load is growing.. - but at any moment you may monitor its "own" IO capacity and correct it if needed
(partially I've already published the results with it before on 5.5: http://dimitrik.free.fr/blog/archives/2010/07/mysql-performance-innodb-io-capacity-flushing.html - it's just a continuation..)
Let's see now how well it works with 5.6 now.. ;-)
First Probe on 32 users Read+Write test
First probe test gave me the same performance level as before, but completely eliminated any presence of async flushing!! However, time ti time I've also observed flush calls burst which were also aligned with purged pages burst.. - Initially I've suspected there is something wrong with server "activity" counter increments (which is now a function since 5.6) and it looked like fixed the issue, but then I've observed it again and supposed that it's possible that something is wrong with METRICS table.. - well, it's a point yet to investigate :-) because according the I/O activity there was no purge burst for example..
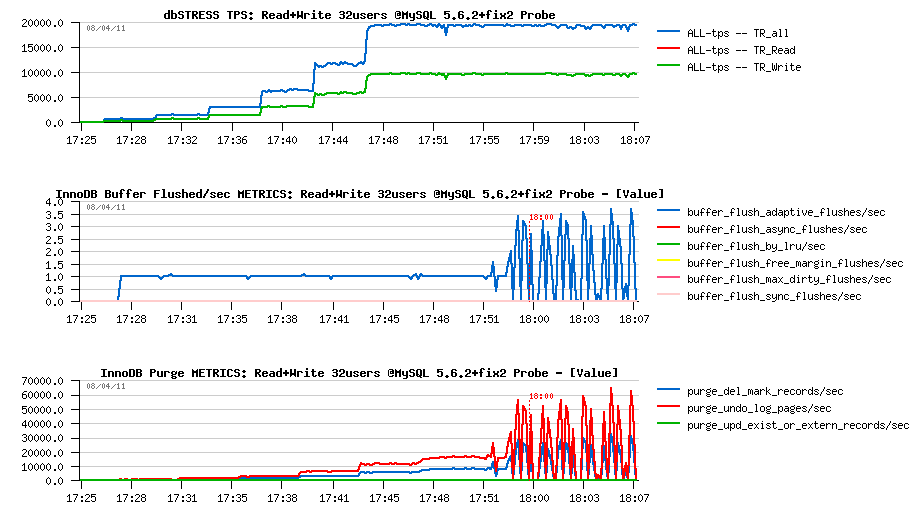
But well, let's call it now "fix2" (so, "fix2" is including "fix1" too) and compare the changes..
Comparing fix2 improvements
First observations :
- async flushing is gone!
- performance is slightly lower due a higher I/O activity..
- Checkpoint Age is stable and probably may be bigger, but I'll keep the same IO capacity setting to be compatible with all previous tests too
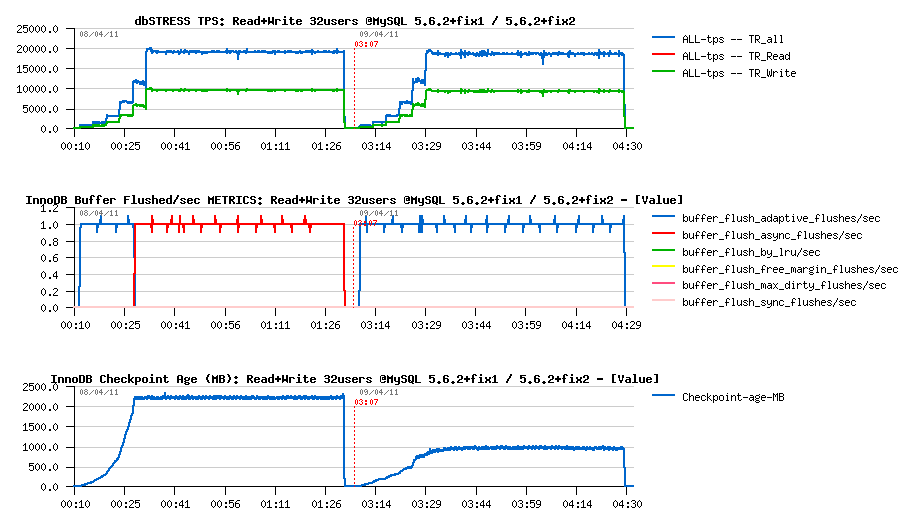
Next :
- max purge lag is still 400K, so the History Length remains stable..
- purge activity also remains the same..
- interesting that contention on "btr_search_latch" was reduced.. ;-))
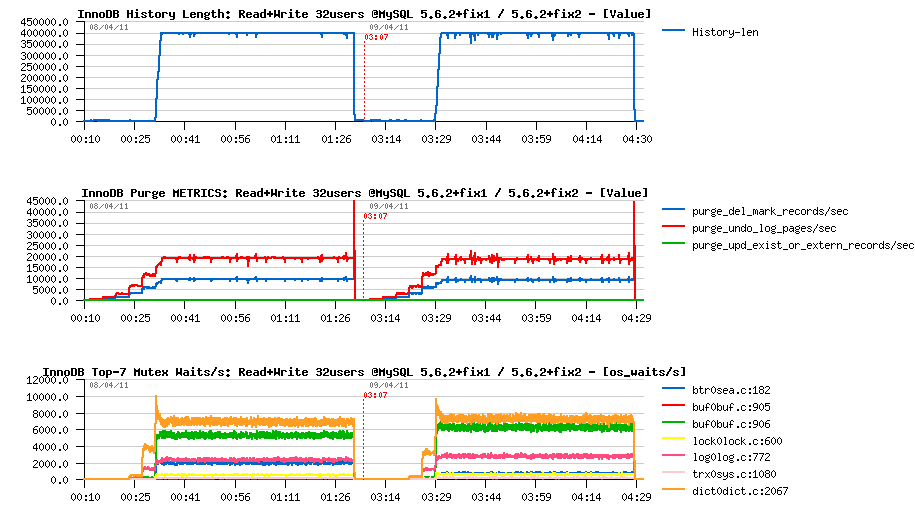
I/O Level :
- however, my SSD disk is looking too fast.. - it's accepting burst writes as well as a constant write load
- at least we may see the write bursts are not present either..
- and it's quite strange to see the disk to be not busy at all.. - what a progress in technology ;-))

Well, time for a full test now.. :-)
Full Test on 1-256 users
Let's compare now 5.5.9, 5.6.2+fix1 and 5.6.2+fix2 on a higher workload - will run the test only up to 256 users to make it shorter. What is important: all databases are running with innodb_max_purge_lag=400000 setting, so let's see what the result will be on the forced to work correctly configuration..
-
Read+UPDATE:
- Performance on 5.6 is better than on 5.5, then "fix2" is removing drops and, curiously, even slightly improving performance
- Only 5.6 is keeping History Length low.. - interesting
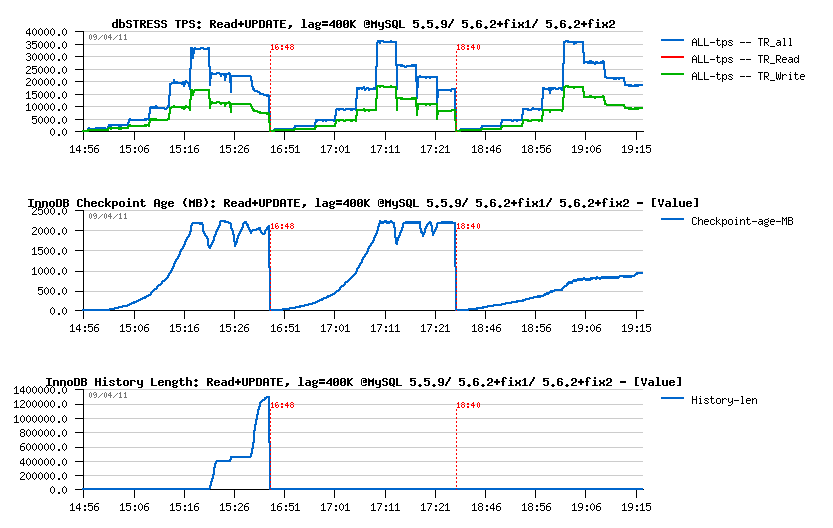
-
Read+Write:
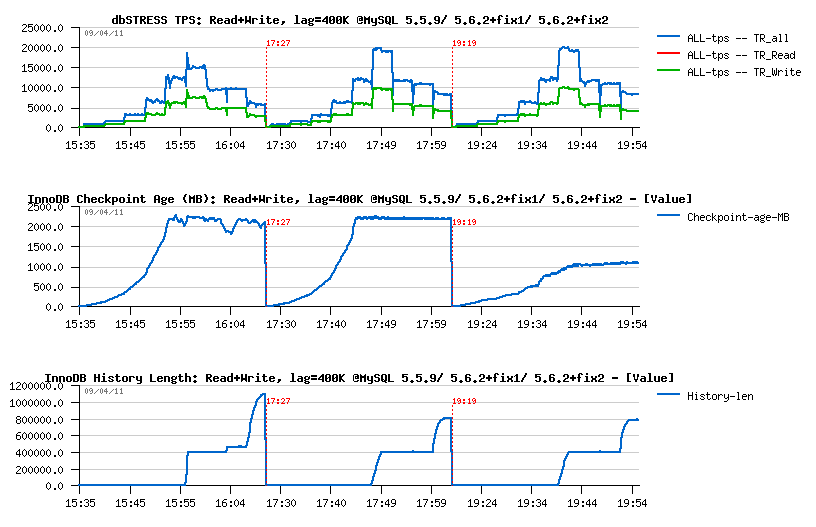
- Performance gain is even more important here on 5.6 as 5.5 was able to keep only 16K TPS on 32 users
- Then, seems like on 5.5 History Length is continuing to grow (need to run on 256 users longer to see if it'll reach some stable level or still not..) - while 5.6 seems to find a purge stability much more easier..
- Interesting also that on 5.6.2+fix2 the Checkpoint age is not changing too much with a growing load.. - looks like SSD performance helps a lot here ;-))
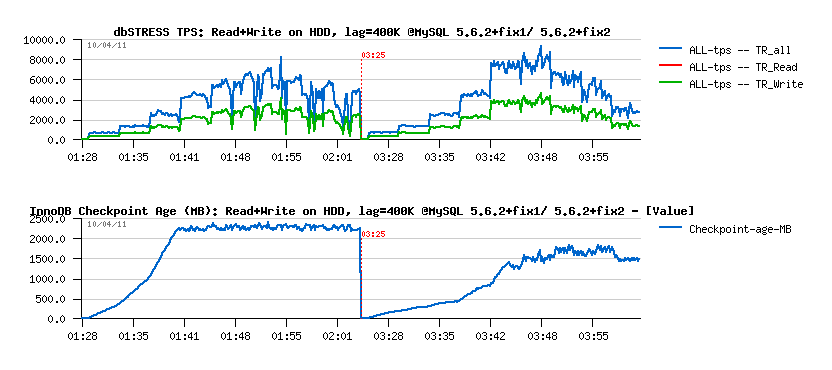
Looking on like SSD is helping, I've executed the same Read+Write test, but placing my data on a RAID with simple disks (software RAID, no controller or cache) - just for fun and to see what will be the difference..
Read+Write Test on HDD
Observations :
- we're far away now from previously seen 20.000 TPS :-) as there is only 9.000 TPS in peak, but in stable max is only 8.000 TPS..
- "fix2" is giving still a more stable performance, but it's also higher! (slightly surprised here)
- even the disks are slow, there is still no async flushing..
Well, I still have many questions here and have to run more tests to clarify things and see if there will be no any background issues, but already what I saw is looking very positive! :-))
And InnoDB team is already progressing in fix of these issues!..
To summarize :
- purge problem is confirmed, fix is available and coming with next 5.6 version
- adaptive flushing improvement: work in progress..
- the reason of contention on "btr_search_latch" was found, work in progress..
- "trx_sys": work in progress, very promising probe results..
- sync array: work in progress, very promising results too..
- there are also other locks became more hot since the "kernel_mutex" contention gone..
It's the final part of the series of "MySQL 5.6 Performance Notes" (other parts are here: 1 , 2 , 3 , 4 )
Any comments are welcome! And if you're lucky to be currently in Orlando, you may come and ask your questions directly - tomorrow I'm presenting "Demystified MySQL Performance Tuning" session Wed, 13th Apr at 10:30am, #305B room.
blog comments powered by DisqusNote: if you don't see any "comment" dialog above, try to access this page with another web browser, or google for known issues on your browser and DISQUS..