« September 2009 | Main | July 2009 »
Wednesday, 26 August, 2009
MySQL Performance: InnoDB Doublewrite Buffer Impact
Recently Mark Callaghan(who I trust a lot) published on his facebook blog a post about a Doublewrite Buffer impact . And Sarah Sproehnle (who I trust a lot too :-)) commented it by saying:
..the doublewrite buffer is actually a benefit. Beyond guaranteeing that pages are recoverable, it also reduces the required fsyncs. Without it, each page that is written to the tablespace would need to be fsync'ed. With doublewrite enabled, a chunk of pages is written to the doublewrite buffer then 1 fsync is called, then pages are written to the tablespace and then 1 fsync...
While I'm completely agree with Mark that we absolutely need a recovery tool to be able at least to repair what is "repairable" (nobody protected from an accident :-)). But on the same time I was curious to measure the doublewrite buffer impact under a heavy read+write workload. I've noted it in my TODO list, but only recently was able to test XtraDB, MySQL 5.4, InnoDB plugin-1.0.4 and MySQL 5.Perf with doublewrite enabled (before I run all my tests with innodb_doublewrite=0 only).
For my big surprise with innodb_doublewrite=1 setting I observed no performance degradation (or near) on all engines! Even the higher rated 5.Perf was still able to keep its TPS level. From the I/O level a flushed volume become slightly higher, but nothing important as you may see from the following graph (the first part of the graph is representing the workload with a doublewrite off, and the second one with a doublewrite on) :
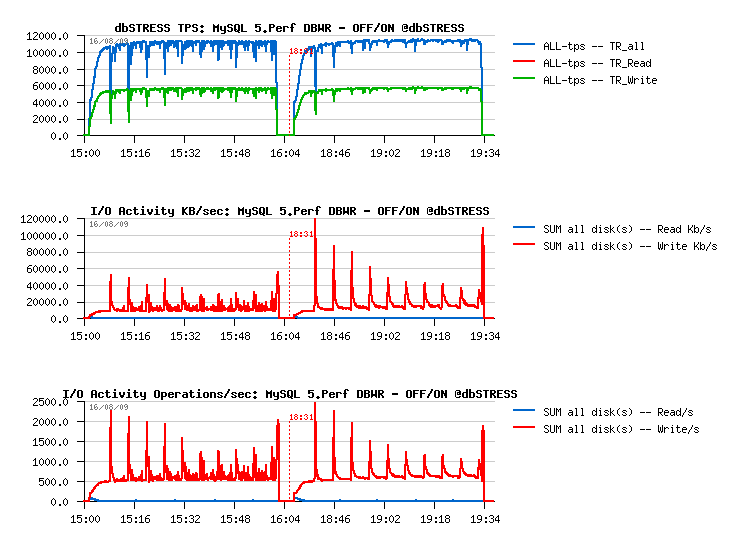
I would even say it brings more stability to the workload! And knowing it also brings more data security - it should be considered as a must option :-)
But now I'm curious : what kind of impact in any other cases was observed by you?...
Thank you for your feedback! :-)
Monday, 17 August, 2009
MySQL Performance: Final fix for Ahead Flushing & Purge Lag
The goal of this post is to tell you a final story about performance study looking to fix the Ahead FLushing and Purge Lag issues.. (I've tried to make it short, but if you feel you'll need more details or just have some more time for reading - go directly to the full report: http://dimitrik.free.fr/db_STRESS_MySQL_540_Purge_Lag_and_Ahead_Flushing_Fixed_Aug2009.html :-))
Before to tell you the story about the final solution, let me show you again the TPS level graph obtained during my last tests:

The read+write workload is executed during one hour non-stop on 4 engines (one by one):
- MySQL 5.4
- InnoDB plugin-1.0.4
- MySQL 5.Perf build #45
- XtraDB-6
As you may see from graph, all engines are getting a periodic performance drops!!
NOTE :
- InnoDB plugin-1.0.4 is using a recently added "Adaptive Flushing" feature !
- XtraDB-6 is using the famous Percona's "Adaptive Checkpoint" !
So, WHY do they also getting performance drops???...
And let me repeat again - just because during a heavy read+write workload and under the current InnoDB design the Master thread is never leaving the purge loop! and whatever "Adaptive" flushing or checkpoint code, as well dirty page limit check is never reached within a Master thread! - (for more details see my initial report and next story )..
(To understand better all these critical points I've instrumented InnoDB with light counters and was able to monitor it live during workload activity (see Extention of InnoDB Status command for more details...))
Initially I've tried to extend a purge loop with ahead flushing to avoid a "furious flushing". Modification is light, but cannot be a true fix because all other Master code should be still executed too...
And then an absolute radical idea changed everything ! :-)
- Tim Cook came with idea: if it's so, WHY NOT isolate a purge processing withing a separated thread ?..
- and Vince Carbone made an initial code split with separated Master and Purge threads!!!
Why having separated purge thread is absolutely great ?! ;-)
- because after that at least all Master thread code will work as expected in any situation!! :-))
- we may leave purging alone looping forever and not take care anymore! :-))
- Master thread activity become way simpler! :-))
It's for what I always loved Sun - it's a place of innovation !! :-))
This idea inspired me to adapt all my changes to the splitted threads and its current logic is working as the following:
Purge :
- it's a separated thread now, just looping alone on trx_purge() call and doing nothing else ! :-)
- initially by design purge should be involved once per 10 sec, but I've made this interval auto-adaptive: if no work was done during the last loop the sleep timeout is increasing (still respecting max 10sec), and if there was some purge work done - sleep timeout is decreasing (still respecting min 10ms) - works just well and adapt itself to the active workload :-)
Master :
- no more purge! :-)
- no more checks for redo log flush! :-)
- flushing redo log within a 1sec loop (as designed)
- do all other stuff within a 1sec or 10sec loop (as designed)
- for the first time on my workload I saw Master thread checking dirty page percentage limit!!! :-)))
Wow! that's is really great!!! :-))
Ahead Flushing
Now, when a dirty percentage limit is really checked, do we still need Ahead Flushing? ;-))
And I will say you YES! :-)
Why?..
-
currently when a dirty page limit is reached there will be a burst
buffer flush with 100% of I/O capacity setting, which may be very
heavy; and setting lower I/O capacity than real will be not good as it
may be too low to flush fast enough (because the goal is to avoid a
critical checkpoint age level)
-
it's quite painful to calculate everytime if dirty page limit is set
correctly according redolog and buffer pool sizes - it'll be much more
better to leave a database engine to take care about, no? ;-)
- there is no a half-force solution: it does not flushing at all, or it's flushing on 100% I/O capacity :-)
So, yes, we need it!
And with a current model with separated threads both Percona's Adaptive Checkpoint and InnoDB's freshly available Adaptive Flushing are entering perfectly in the game now! :-)) However I wanted absolutely to test a final solution but both "Adaptive" codes were not directly adaptable for MySQL 5.4... So I've made mine :-) with a small personal touch :-))
You may find all details about within a final report , but I'll just show here that from the previous situation:

we moved to the following one:

Few comments:
- no more periodic performance drops!
- checkpoint age is staying under 1.2 GB - probably a shorter time in case of recovery? ;-)
- critical checkpoint age is never reached! :-)
- mainly the buffer flushing is involved from Ahead Flushing code
- and still no more than one flush per second is really executed..
Everything goes pretty well now.. except a constantly growing "History len" value...
Purge Lag
Observing my workload graphs I was surprised by seeing a constantly growing "History len" value - this number is represiting the current number of un-purged pages..
Why it happens and where is a danger you may find from MySQL manual:
In the InnoDB multi-versioning scheme, a row is not physically removed from the database immediately when you delete it with an SQL statement. Only when InnoDB can discard the update undo log record written for the deletion can it also physically remove the corresponding row and its index records from the database. This removal operation is called a purge, and it is quite fast, usually taking the same order of time as the SQL statement that did the deletion.In a scenario where the user inserts and deletes rows in smallish batches at about the same rate in the table, it is possible that the purge thread starts to lag behind, and the table grows bigger and bigger, making everything disk-bound and very slow. Even if the table carries just 10MB of useful data, it may grow to occupy 10GB with all the "dead" rows . In such a case, it would be good to throttle new row operations and allocate more resources to the purge thread. The innodb_max_purge_lag system variable exists for exactly this purpose.
(see http://dev.mysql.com/doc/refman/5.0/en/innodb-multi-versioning.htmlfor more details)
In my case every time when the test is finished it still took 15-20 minutes for InnoDB to flush all dirty pages!
Observations:
- History len is outpassing 6 millions
- once the workload is finished, InnoDB is starting to decrease a purge gap
- dirty pages level cannot reach zero value until history len is not become zero too
- it took 17 minutes to free all dirty pages!
This workload was kept during one hour. But what will be after a whole day activity?..
The problem seems to come due the fact that purge thread cannot follow the workload activity - there are too much pages to purge...
What kind of solution may be used here?
-
speed-up the purge processing (even it may be quite costly - there are
many user threads modifying data, and only one purge thread cleaning
removed rows - so there will be need to have several purge threads,
and it leave less CPU power for a useful work (and finally you'll
probably not win anything for your workload throughput) - however even
single thread currently is not going on its full speed as it's
crossing some common locks with other threads during its work..) - but
with time I think this direction will get the main priority!..
- add a kind of throttling for writing operations to keep their activity on the same level as your maximum possible purge throughput - it'll slow down little bit your transactions, but avoid a big potential disaster!..
The second solution is already implemented within InnoDB - you may set an innodb_max_purge_lag parameter to say InnoDB to keep purge gap under this limit. But! The only problem - it doesn't work here..
WHY?..
As I explained in my previous report , the innodb_max_purge_lag condition is ignored until InnoDB considering there is a consistent read view which may need see rows to be purged. The problem is I don't have a feeling it works properly, because until I have any SELECT within my workload InnoDB considering them as consistent reads, even they are started way after when the last DML statement was committed. Probably keeping a track of an oldest LSN for SELECT may help?.. But well, let's back to the innodb_max_purge_lag setting:
This variable controls how to delay INSERT, UPDATE, and DELETE operations when purge operations are lagging (see Section 13.2.9, ?InnoDB Multi-Versioning?). The default value 0 (no delays). The InnoDB transaction system maintains a list of transactions that have delete-marked index records by UPDATE or DELETE operations. Let the length of this list be purge_lag. When purge_lag exceeds innodb_max_purge_lag, each INSERT, UPDATE, and DELETE operation is delayed by ((purge_lag/innodb_max_purge_lag)×10)?5 milliseconds. The delay is computed in the beginning of a purge batch, every ten seconds. The operations are not delayed if purge cannot run because of an old consistent read view that could see the rows to be purged.
(see http://dev.mysql.com/doc/refman/5.0/en/innodb-parameters.html#sysvar_innodb_max_purge_lag)
But honestly - what is the problem with DML query delay and consistent view?.. If the innodb_max_purge_lag is set it means we want to avoid any purge lag higher than this value! And if it become higher and there are new insert/delete/updates arriving - what else can we do here if we will not delay them just little bit? The same thing may be made within a customer application (if things going slowly - add few ms sleep between transaction orders) - will it be broken after that? ;-)) The same logic is implemented within many file systems (and recently in ZFS too)..
So, my fix is simple here - by removing of consistency read check within trx_purge function! :-)
In short the:
if (srv_max_purge_lag > 0
&& !UT_LIST_GET_LAST(trx_sys->view_list)) {
become:
if (srv_max_purge_lag > 0 )
{
As well I limit the max potential delay value to 50ms.
The result
And now let me present you the result - following test was executed with Purge lag fix applied and innodb_max_purge_lag = 200000 limit:

Observations :
- TPS level is slightly lower - from 8,200 TPS it moved to 7,800 (400TPS less, 5% performance loss)
- however, everything else looks just fine! :-)
- history len is stable on 200000
- max DML delay did not outpass 5ms during all test duration
- checkpoint age and dirty pages level are rock stable
- and the most fun: once the test is finished, instead of 17 minutes all dirty pages were freed within 30 seconds ! :-)
More details you may find from the full report: http://dimitrik.free.fr/db_STRESS_MySQL_540_Purge_Lag_and_Ahead_Flushing_Fixed_Aug2009.html
Any comments are welcome! :-)
Sunday, 16 August, 2009
Butterfly & Summer...
X-files category grouping all posts "about nothing" :-) or just yet more another occasion to say that life is beautiful and plenty of surprises! :-)
Hard to resist and not to think about life beauty while looking on a butterfly... :-)
But when you discover such beautiful specimens inside of your proper garden - you find yourself smiling like a child :-)
Large Tortoiseshell / Grande Tortue & Peacock / Paon du jour

|

|
The most common, but so fun :-)
The Swallowtail / Machaon

|

|
Don't know why, but Machaon was always my preffered butterfly as far as I remember myself :-) The King (or Queen) Butterfly - as you prefere :-)
Scarce Swallowtail/ Flambé

|

|
Very beautiful butterfly, seems to be very rare nowdays in France... We're happy they like our garden! :-) Flambés and Machaons are flying like birds... And the most magic is to observe them plane..
***
But well.. When butterflies are gone - Summer is finished...
Thursday, 13 August, 2009
MySQL Performance: InnoDB plugin-1.0.4 & others @dbSTRESS
This post is an update of my previous one about XtraDB-6 performance - as InnoDB plugin-1.0.4 announce came the same day I did not have yet any benchmark results on that time :-)
To be short, the new InnoDB plugin looks very positive and have several very valuable improvement (and of course we expected to see them much more earlier, no? ;-) on the same time analyzing all latest updates - probably it's the first sign that things will go much more faster in the near future? ;-)
Anyway, what I liked with this release:
- group commit is back! (and we should thank a lot Percona team for their efforts to get it fixed! ;-)
- configurable number of I/O threads and I/O capacity (aligned now with XtraDB, Google patched and MySQL 5.4)
- adaptive flushing (idea is similar to Percona's Adaptive Checkpoint, but more elegant)
- read ahead algorithm changes
- etc..
Full list of changes you may find from InnoDB changelog , (as well Mark Callaghan wrote a very good summary about, and hope you did not miss Yoshinori's post about his group commit tests ).
InnoDB plugin is missing a timer concurrency model for the moment. Probably it will come with the next release? ;-)
But what about results on dbSTRESS?..
Read-Only Workload
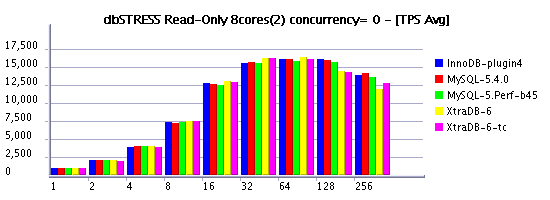
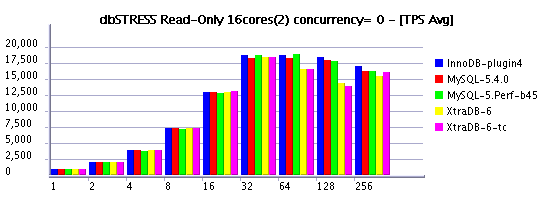
Observations :
- with the latest Solaris 10 update7, MySQL is scaling better now on the read-only workload even with setting concurrency to zero!
- InnoDB plugin looks very stable!
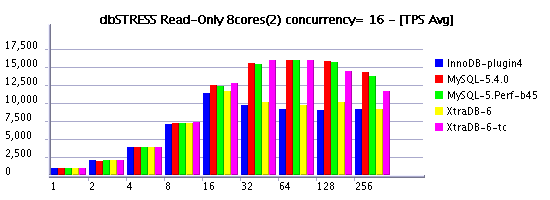
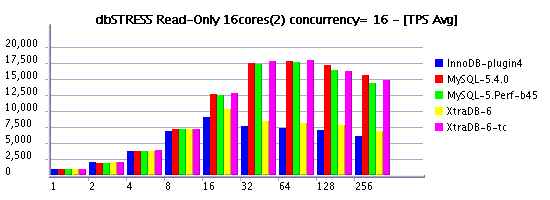
Observations :
- while concurrency setting is not zero, only engines using a timer based model continue to keep workload
- we may also ask as well: why use concurrency setting if the result is alredy "good enough"?.. - well, if you have only reads - it's ok.. But what if you also have writes? ;-)
Read+Write Workload
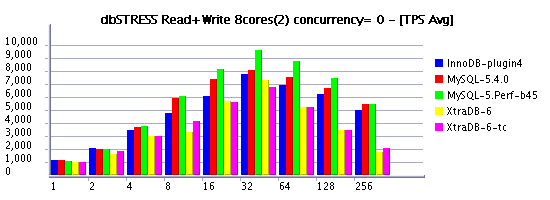
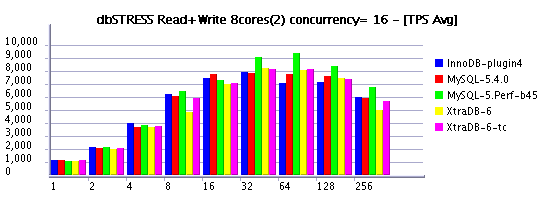
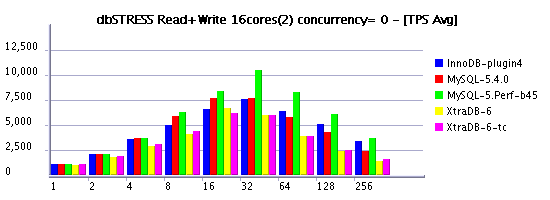
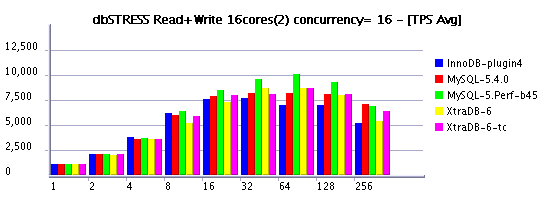
Observations :
- as you may see, limiting thread concurrency on the read+write workload helps a lot to keep a growing load!
- depending on how many active & concurrent sessions you have on your workload you may choose your optimal setting..
All other results as well all other details about this testing you may find from my full report: http://dimitrik.free.fr/db_STRESS_XtraDB_6_and_InnoDB_plugin_4_on_M5000_Aug2009.html
Long duration Read+Write Workload
I've also mentioned before the test is not log enough to reach the highest TPS level of each engine. For my other performance analyzing I've set up a long (1 hour) non-stop Read+Write test:
- 5min Read-Only warm-up
- 60min non-stop Read+Write
- 32 concurrent sessions
- 16 CPU cores
- 50GB database
So, let me show a small graph:
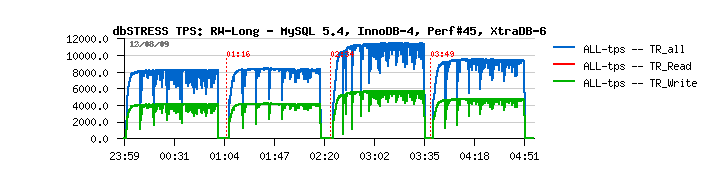
The blue curve is representing a TPS level reached during this workload. There were all 4 engines tested one after other: MySQL 5.4, then InnoDB plugin-4, then MySQL.Perf build #45, and finally XtraDB-6. As you may see the throughput still continues to grow within 10-15 minutes, and only then reaches its higher level and become stable. So, the max (and stable!) Read+Write throughput will be:
Engine TPS MySQL 5.4 8,200 InnoDB plugin-1.0.4 8,300 XtraDB-6 9,500 MySQL Perf build #45 11,500
Curiously I've already observed 12,500 TPS before with Perf build #5...
(need to check if we did not break something with a time here..). But
performance improvements made within the latest releases of XtraDB and
InnoDB plugin are very impressive!
I may only say: Please, DON'T STOP! :-)
Any comments are welcome! :-)
Tuesday, 11 August, 2009
MySQL Performance: XtraDB-6 & others @dbSTRESS
I'm happy to present you my first benchmark results with XtraDB-6 on dbSTRESS. Percona team made a huge work preparing this release and there are really a lot of improvements regarding performance as well general usage (for more details about XtraDB-6 see the full announce from Percona site).
But my main interest is around performance (sorry :-)), and I was curious how well now XtraDB-6 resists to the stress workload. New release also integrating the "timed based" concurrency model introduced within MySQL 5.4 - missing this feature was negatively impacted XtraDB in previous tests. But now we may expect it runs at least as fast as MySQL 5.4! Let's see...
Tested versions
- MySQL 5.4.0
- MySQL 5.Perf (build #45)
- XtraDB-6
- XtraDB-6-tc (configured with "timed concurrency")
All engines were compiled from sources with GCC4.3. All binaries are using GCC atomics.
I'm not publishing a full report here yet as there was another announce today - InnoDB plugin-4 was released :-) so I wish to complete it with plugin results too :-)
But well, few graphs are more then words..
Read-Only Workload (RW=0)
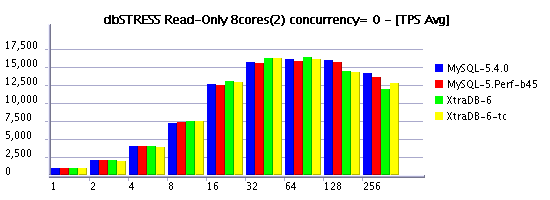
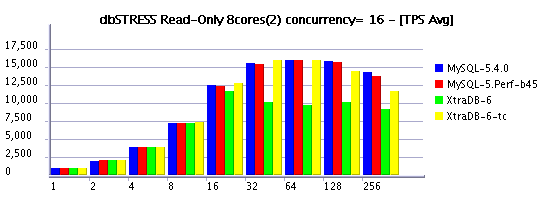
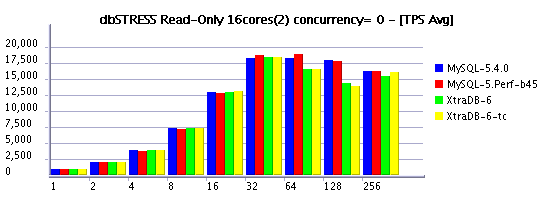
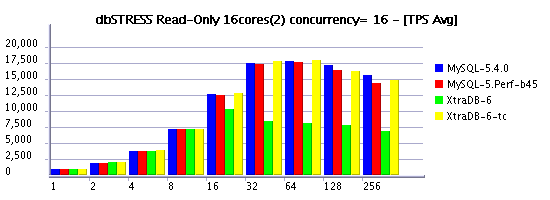
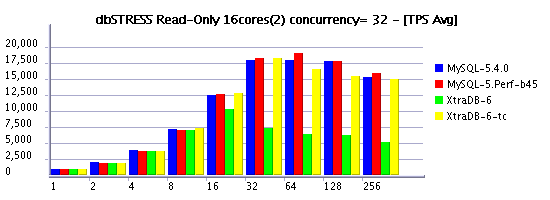
Observations :
- several times XtraDB-6 outperforms MySQL 5.4 now! - my congratulations to Percona team!!!
- now on read-only workload the difference between concurrency settings is near to zero (Solaris 10 update7 helps a lot here!)
- timed concurrency model is still more optimal vs original
- good to see performance increasing when moving from 8 to 16 cores, but I'd expect more, not you? ;-)
Read+Write Workload (RW=1)
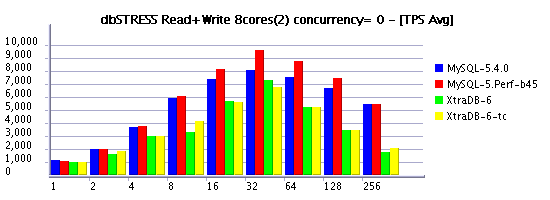
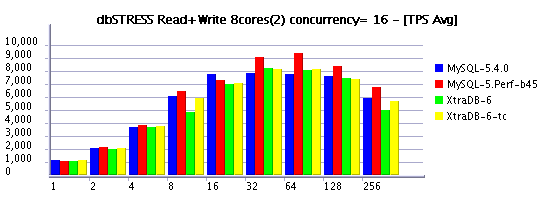
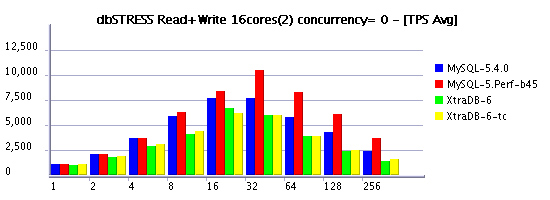
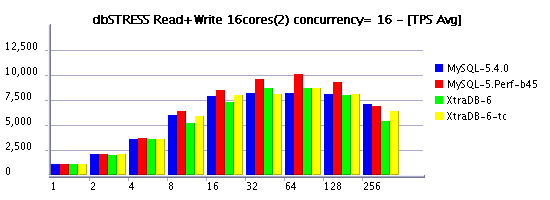
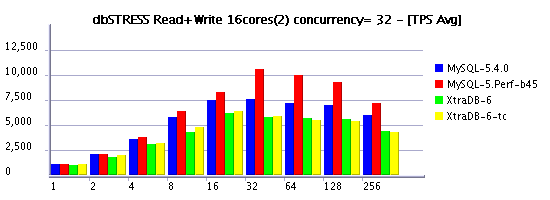
Observations :
- limiting the concurrency is the must to keep read+write workload of more than 32 sessions
- in several cases XtraDB is outpassing 5.4 again!
- build45 demonstrating the best performance here
- moving from 8 to 16 cores still improving performance, but hope one day we'll see x2 times difference! :-)
10Reads/Write Workload (RW=10)
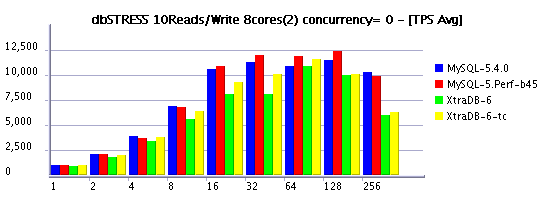
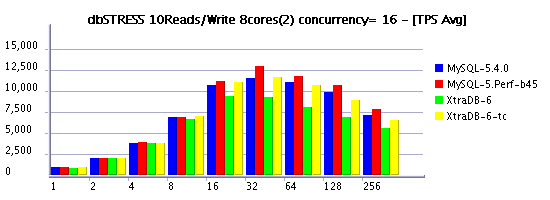
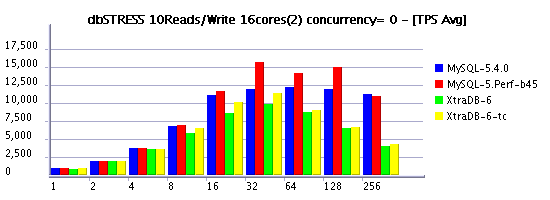
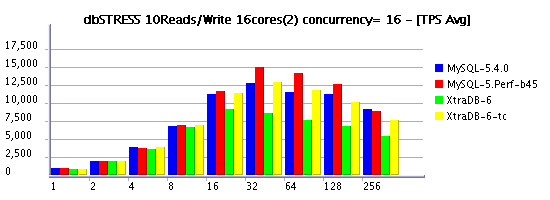
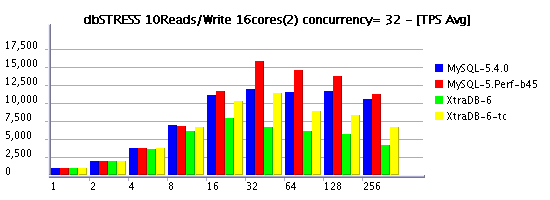
Observations :
- 10Reads per Write (RW=10) is less aggressive on writing and may represent a more common kind of workload for some users, and as you see limiting concurrency helping again to keep higher workloads and lower performance decreasing..
- timed model is more optimal again
- in some cases XtraDB performs better then 5.4, in some cases it's 5.4
- but build 45 is still the best, seems the its main improvement was made on writing, and it confirms other our observations..
Other results are coming soon! Well done, Percona!!! My sincere congratulations! To outperform 5.4 was not an easy task! ;-))
Any comments are welcome :-)