« June 2012 | Main | January 2012 »
Friday, 20 April, 2012
Moving to DISQUS Comment system
The Echo Comments service that I've used for years until now will be EOL-ed in few months and discontinued.
So, I'm moving my site to another comment system called DISQUS. The export/import formats between these systems are completely different and most of data needed for DIQUES are missed, so I'm in way to copy/paste most of conversation threads as a single comment block, still keeping author names and discussion less or more readable ;-)
Sorry if some of data will be lost at the end - it was not intentional..
-Dimitri
Friday, 13 April, 2012
MySQL Performance: 5.5 and 5.6-labs @TPCC-like
It's now over a year when there was a quite interesting exchange with
Vadim and other Percona guys due their TPCC-like benchmark results on
MySQL 5.5 - I've replayed on that time the same tests, but with a better
tuned configuration parameters to demonstrate that with a little bit
more love, MySQL
5.5 may keep TPCC-like workload very well ;-)) However, it was clear
that Adaptive Flushing in 5.5 needs
some improvement (which is now
implemented in 5.6), but there were also several open questions
regarding I/O level and O_DIRECT performance which I was able to clarify
for me only during last
year IO testing on a decent Linux box + storage..
Summarizing
all this stuff, you may understand my curiosity to see how well (or not)
MySQL 5.6-labs is running today on Percona's TPCC-like workload ;-))
But
let's start from the system setup first:
- so, I'm using a 32cores bi-thread Intel box, 128GB RAM
- running Oracle Linux 6.2
- storage: x3 SDD in RAID0
- filesystem: XFS mounted with "noatime,nodiratime,nobarrier,logbufs=8" options
Same TPCC-like workload as before:
- 500W data volume
- 32 concurrent users (initially it was only 16 on the previous tests, but I think it'll be pity to run only 16 users when you have 32cores Linux box ;-))
Then, my first test will be with MySQL 5.5 - even it's GA since more than one year and no any major changes allowed to the code, it was still improved over a time and will give us a good idea about its state for today.. From the previous testing I've retained that to help Adaptive Flushing in 5.5 the "innodb_io_capacity" value should be set to a something huge -- as the algorithm in 5.5 is not following very well the REDO activity, we should avoid to limit it in IO capacity (and when it'll decide to do a big I/O request we should let it happen ;-))
MySQL 5.5 configuration:
[mysqld]
max_connections=4000
table_open_cache = 8000
back_log=1500
query_cache_type=0
# files
innodb_file_per_table
innodb_log_file_size=1024M
innodb_log_files_in_group=3
# buffers
innodb_buffer_pool_size=64000M
innodb_buffer_pool_instances=16
innodb_log_buffer_size=64M
# tune
innodb_checksums=0
innodb_doublewrite=0
innodb_support_xa=0
innodb_thread_concurrency=0
innodb_flush_log_at_trx_commit=2
innodb_flush_method= O_DIRECT
innodb_max_dirty_pages_pct=50
# perf special
innodb_adaptive_flushing=1
innodb_read_io_threads = 16
innodb_write_io_threads = 16
innodb_io_capacity = 20000
innodb_purge_threads=1
Note that I did not reduce this time the dirty pages percentage to enforce the dirty pages flushing - I'm expecting here that my I/O level will be fast enough to keep the flush activity aligned with REDO logs.. Let's see what is the result now ;-)
MySQL 5.5 results:
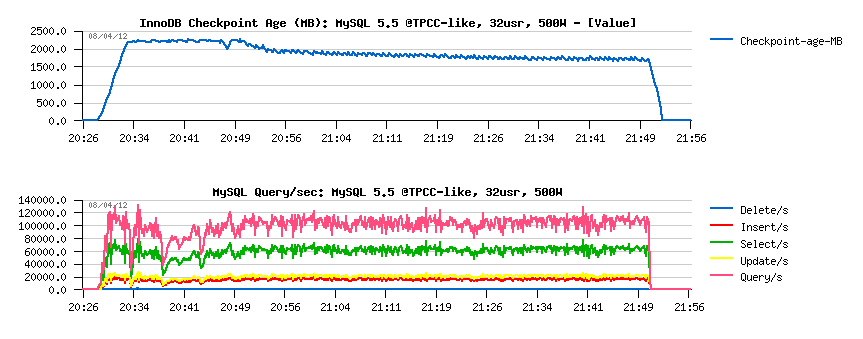
Observations :
- there are some initial QPS drops due critical levels in Checkpoint Age
- but over a time performance become more and more stable, reaching something not far from 110K QPS..
Well, lest move to MySQL 5.6.4 now - it was the last 5.6 release just before 5.6-labs, so Adaptive Flushing was still very similar to what we have in 5.5 (even if some improvement, like page_cleaner thread, were introduced).. So, nothing different within 5.6.4 configuration setup (same 20K IO capacity), except monitoring via METRICS table is enabled.
MySQL 5.6.4 results :
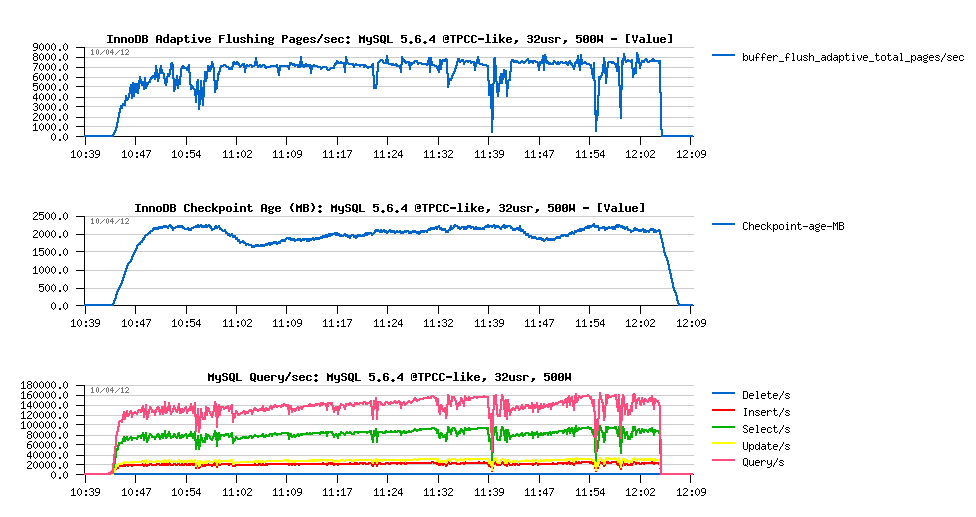
Observations :
- QPS performance is reaching 160K QPS over a time
- there are more activity drops comparing to 5.5..
- all QPS drops are related to reaching critical levels in Checkpoint Age.. - so it was a time to improve AF here ;-))
- we're reaching near 8000 pages/sec in flushing - good to know to adapt the Max IO capacity in 5.6-labs ;-)
MySQL 5.6-labs configuration:
- same as 5.5, except the following:
- innodb_io_capacity = 4000
- innodb_max_io_capacity = 12000
MySQL 5.6-labs results :
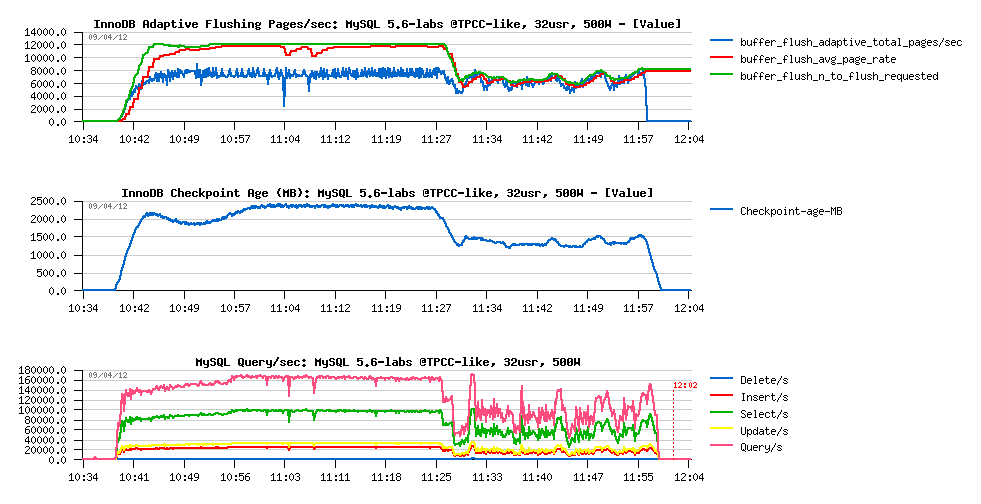
Observations
- seems we're unable to flush more than 8000 dirty pages/sec here.. (interesting why?..)
- so, nothing surprising that Checkpoint Age is remaining in critical level most of the time..
- however, there are near no QPS drops at all on the "good" part of graph (up to 11:25 ;-))
- we're reaching 170K QPS now !..
- but after 11:25 there is a huge performance drop.. - why?..
Let's look more in depth:
- the main current InnoDB bottleneck on TPCC-like workload is index lock contention..
- but since 11:25 there is a log_sys mutex contention which is jumping up too!..
- the only reason for log_sys to come in such a configuration is to get REDO log files out of filesystem cache (then on most of REDO I/O writes there will be read-on-write involved, because the REDO I/O operation is not aligned to the filesystem block size..) - this will be fixed soon in 5.6 too ;-)
- however, since I'm using O_DIRECT, and only MySQL is running on my server, what other I/O activity may remove REDO log files from the filesystem cache?...
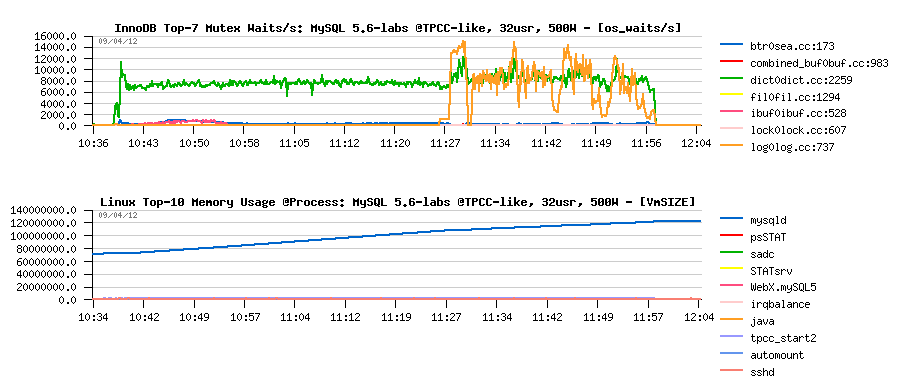
The answer:
- from the graph above you may see that "mysqld" process is reaching 128GB memory usage by the end of test..
- of course, when there is no more memory on the system, there is no more place for REDO logs in the filesystem cache either ;-))
- comparing with 5.6.4, seems there was a memory leak bug introduced in 5.6 trunk recently ;-))
- so, I'm happy to find it, but keep it in mind for the moment when trying 5.6-labs on Read+Write workloads - I think it'll be fixed soon..
Well, I'm pretty happy with what I saw.. (except the memory leak bug of course ;-)) -- but I see now the potential we're having under 5.6-labs.. And with all other further improvement which are currently in pipe, MySQL 5.6 should be again yet another the best ever MySQL release after 5.5 !..
Stay tuned.. ;-)
Rgds,
-Dimitri
MySQL Performance: Improved Adaptive Flushing in 5.6-labs
I'd start this blog post with "I've had a dream".. ;-))
Seriously,
it was my dream from a long time that "official" MySQL code comes with a
more improved Adaptive Flushing solution in InnoDB.. - and now, with
5.6-labs release, this dream becomes a reality ;-))
The story
with Adaptive Flushing is so long.. Started by Yasufumi after his
brilliant analyze of the flushing problem in InnoDB, then integrated in
XtraDB as Adaptive Checkpoint, then came in alternative way as Adaptive
Flushing in "official" InnoDB code, then yet more improved within
Percona Server, etc. etc. etc.. (my last
post about was one year ago, and it was already a call to action
rather a general discussion about performance improvements ;-))
However,
it took a time to get similar improvement within an "official" InnoDB
code, but not because people are lazy or not open to changes, but just
because the already implemented solution within InnoDB was simply "good
enough" in many cases ;-)) specially with appearing of the page_cleaner
thread in 5.6.. The only weak point it has is that it's unable to keep
load spikes (but in this point no one of existing solutions is good,
even in XtraDB), and it may take a long time before to "adapt" to a
given workload..
Let's get a look on the following graph: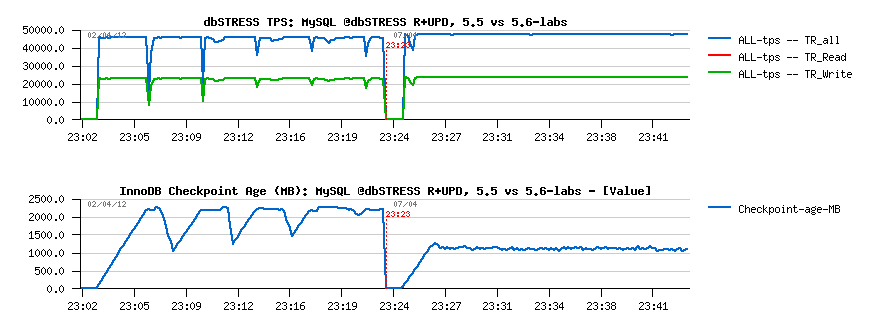
Explanations:
- this a light dbSTRESS RW workload with 32 concurrent user sessions
- MySQL 5.5 and 5.6 are both having a similar drops in TPS level (left part of graph)
- these drops are due Checkpoint Age reaching max REDO log space
- so urgent burst flushing (furious flushing) is involved to create a room of free space within REDO, otherwise the whole transactional processing is remaining frozen..
- however, over a time such drops are less and less important, so some users may probably even live with it..
- but on the right part of the graph you may see 5.6-labs solution in action, and there is no more any drops at all (except the initial one which is related to adaptive hash index initialization)
- as well, 5.6-labs is keeping a quite significant marge in Checkpoint Age in case there will some spikes happen in the load with increased activity (where 5.5 will almost have TPS drops every time..)
To be sure we're not reinventing the wheel, we even ported most interesting solutions to the 5.6 prototype trunk, and I've tested all of them on the more hard RW workload:
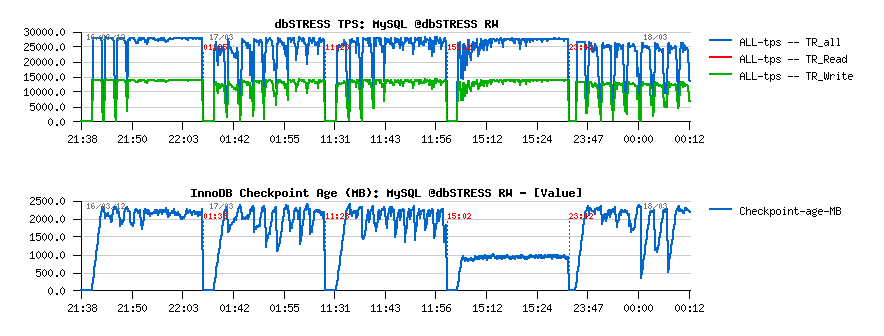
From the left to right:
- 5.6-native
- 5.6 + "estimate" from Percona
- 5.6 + "keep avg" from Percona
- 5.6-labs
- Percona 5.5 (this one I've tested just to be sure nothing was wrong with a logic in a ported code)
As you may see directly from these graphs that our solution (implemented now in 5.6-labs) looked more attractive from the beginning.. And I'm very happy to be able to contribute to it, as several of my previously expressed ideas were accepted to be a part of this solution too ;-))
So, what was changed in the improved Adaptive Flushing (AF) in MySQL 5.6-labs:
- first of all the logic is moved to the REDO log space occupancy rather tracking estimation of pages to flush as before
- more REDO space is filled, and more aggressively becomes InnoDB is flushing
- less REDO is filled - more relaxed is flushing..
- the relation between REDO occupancy and flushing power level is progressive and non-linear..
- all the time we're also considering the average REDO filling speed and average amount of flushed pages
- these averages are helping to guide the AF decisions to better adapt dirty pages flushing according database activity..
- then only point which is remaining yet open is a case when pages flushing is unable to follow REDO writes simply because of weak I/O layer.. - we already have a solution here too, but it's not yet part of 5.6-labs ;-)
From the user/DBA point of view the AF configuration as looking as simple as following:
- the IO capacity setting is still remaining (and used for most maintenance tasks within InnoDB - you should consider it now as kind of AVG I/O write activity you're expecting to see from your database server in general, specially useful if your MySQL server is running with many other applications on the same machine (or other MySQL instances as well))..
- the "Max" IO capacity is introduced to say how high InnoDB is allowed to go in flushing to be able to follow REDO log activity
- the Low Watermark is introduced to say since what percentage of REDO log space filling the AF processing should be activated - depending on your workload it may vary.. (default is 10%)
- all configuration variables are dynamic and can be changed at any moment ;-)
So, once you've set your limits - InnoDB then will try to do the best with what it has :-)
And all AF internals are available for monitoring via METRICS table:
- buffer_flush_adaptive_total_pages -- getting delta of this value divided by the time interval giving you the current speed of pages flushing due AF
- buffer_flush_avg_page_rate -- the average pages flushing rate seen and considered within AF, and if everything is going well with your I/O level, this value should less or more follow the previous one ;-)
- buffer_flush_n_to_flush_requested -- the amount of pages requested for flushing by AF (and which may be quite different from both previous counters because the avg REDO filling speed is also coming in the game, and may limit a real flushing by pages age)..
- buffer_flush_lsn_avg_rate -- LSN avg rate seen by AF (corresponding to the REDO logs feeling speed and used as age limitation barrier when flushing is involved -- so we may then flush as many pages as requested or less, because of this age rate).. - when on the I/O level everything is going well, this value should less or more follow your REDO MB/sec write speed, and grow in case of lagging to increase the current age barrier for flushing..
There are also some other counters, but let's skip them to keep stuff simple ;-)
Now, replaying the same RW workload presented before on MySQL 5.6-labs with:
- innodb_io_capacity = 2000
- innodb_max_io_capacity = 4000
will give us the following:
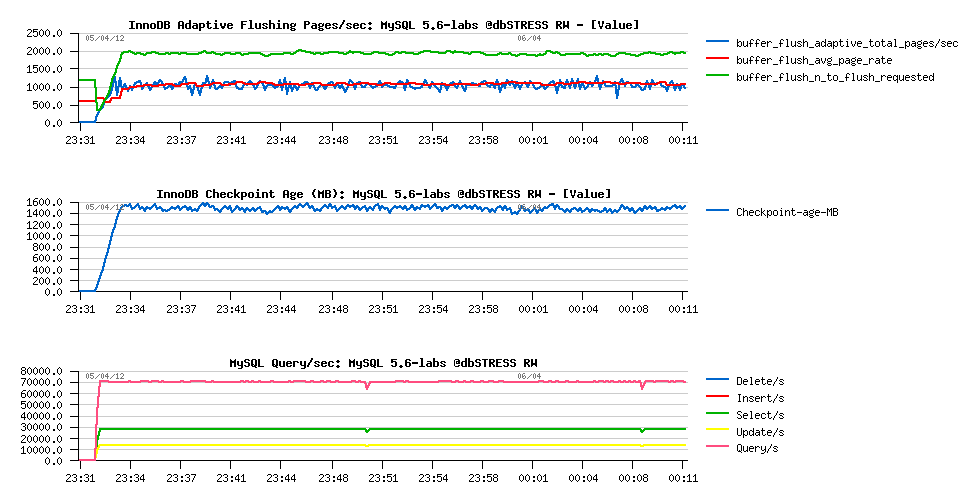
So,
- AF is requesting to flush 2000 pages according its estimation
- but in reality flushing 1000 pages/sec is quite enough to keep Checkpoint Age on a reasonable level
- 70K QPS is reached..
But what will be changed since there will be some activity spikes?..
I'll mix now this workload with Sysbench OLTP_RW - additional 16/32 users sessions will come and leave the database activity with their RW transactions:
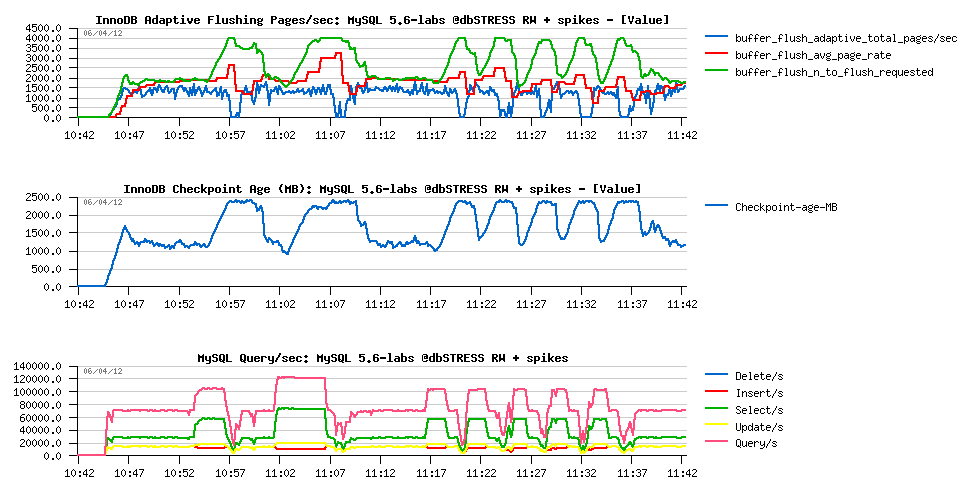
Observations:
- Checkpoint Age is jumping up during spikes in activity..
- within a current I/O configuration InnoDB is unable to flush faster than 1500 pages/sec..
- which is resulting in QPS drops during these spikes..
-
What can we do to help here?..
- we may improve the I/O level performance (sure will help! ;-))
- or expect that is the spikes are not too long in time, with a bigger REDO logs there will be more room to resist to them..
So, now replaying the same test case, but now with using 8GB REDO logs total space:
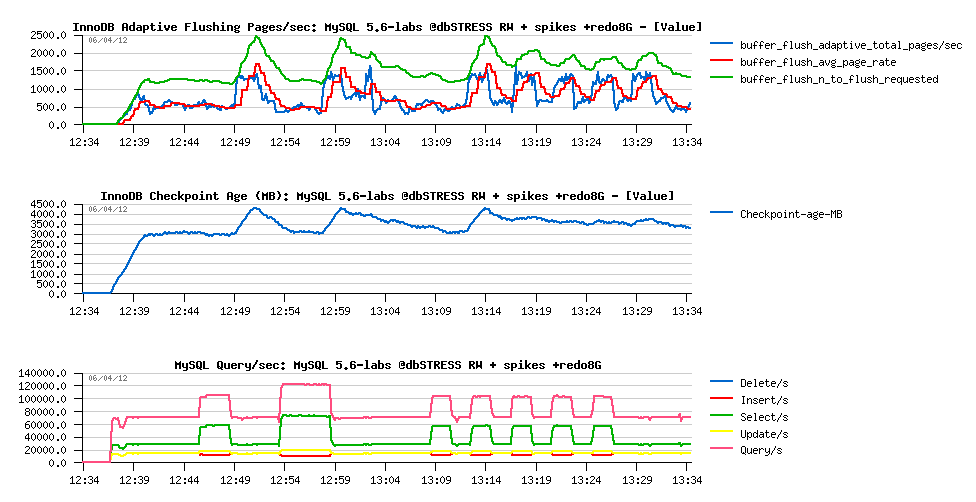
Observations:
- having a bigger REDO space automatically reduced the flushing rate during "quiet periods" (from 1500 to 500 pages/sec)
- and we're reaching 1500 pages/sec flushing only during spikes now..
- the marge on the REDO log space is big enough to keep Checkpoint Ages jumps under critical level
- which is resulting in a total absence of QPS drops ;-)
Or the same workload on a served with less powerful CPUs, but more powerful storage level:
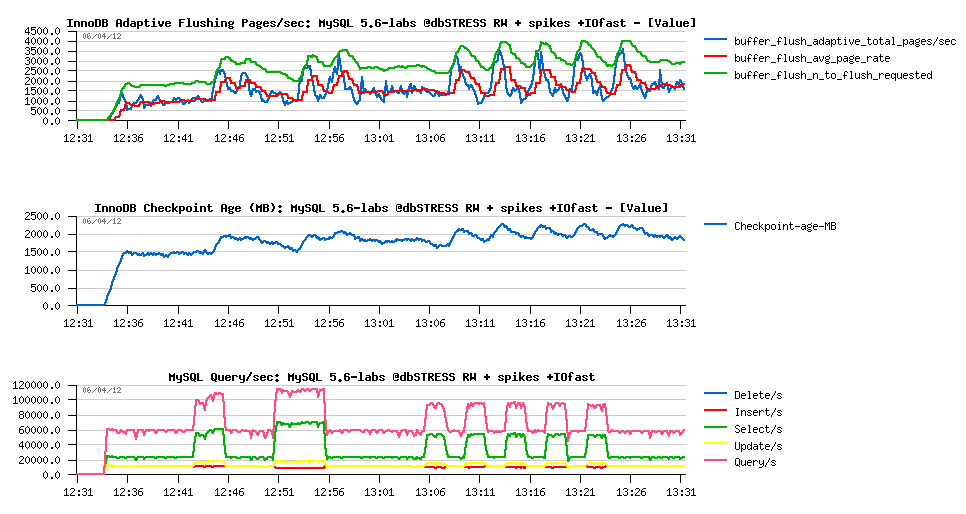
Observations:
- QPS level is lower due lower CPU speed
- but dirty pages flushing level is way faster when requested, easily reaching 3000 pages/sec
- so we're not observing any QPS drops on activity spikes as Checkpoint Ages levels were never critical..
Looking on these results we may be only happy, because none of ones was possible to achieve with MySQL 5.5 and previously in 5.6 (both will keep Checkpoint Age too close to the critical limit, so any activity spike will bring a TPS drop)..
After these "complex" tests, let's get a look on a "simple" Sysbench OLTP_RW between 5.5 and 5.6-labs:
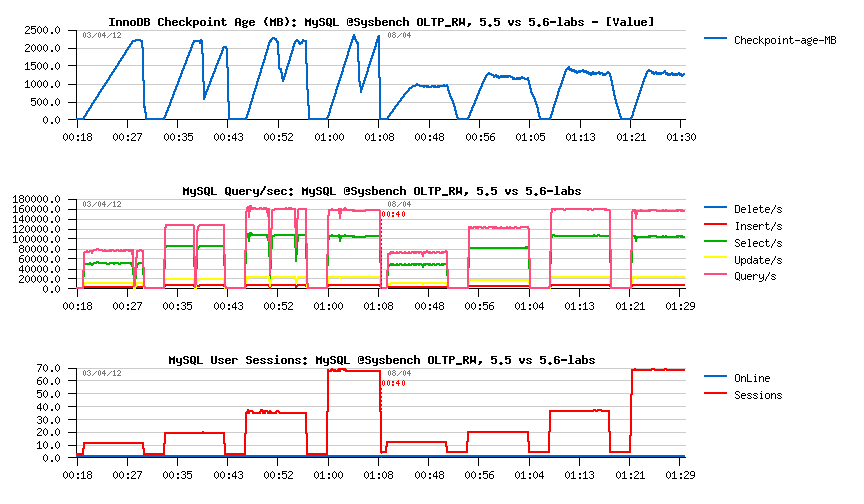
As you can see, as soon as you have to flush due reaching critical Checkpoint Age levels - as soon you'll have TPS drops too.. It's what we're observing in 5.5 and before in 5.6 - but I hope time is changed since 5.6-labs ;-))
The solution is not yet final, but at least very promising and pretty easy to tune ;-) but more testing will give us more ideas about how the final code should look like.. - so don't hesitate to test it on your own systems and your own workloads!! ;-))
As the final word, I'd like to thank Inaam from InnoDB team for his patience in implementation and adoption of all the ideas we have around into a single and truly integrated within InnoDB code solution!.. Kudos Inaam! :-))
I'd say, and you may just trust me, since 5.6-labs benchmarking MySQL will become much more interesting! ;-))
Rgds,
-Dimitri
Tuesday, 10 April, 2012
MySQL Performance: 5.6-labs is opening a new era..
I think every performance engineer in his life is time to time meeting some curious performance problems within an application (not only MySQL) which is looking out of understanding and over a time only continuing to increase a headache.. (until not resolved, of course.. ;-))I've met many of them in the past while working in the Sun Benchmark Center, but did not expect to meet it so soon once started my official work in MySQL team ;-))
The problem is looked as simple as nothing else, and that's why it was several time more painful than anything else too :-))
Let me explain: since of the beginning of this year I've got for MySQL performance testing a 32cores (bi-thread) Intel server running Oracle Linux. And ss soon I've got it, I've deployed my tools on it and started my tests..
The main surprise for me came on the Read-Only test:
- what can me more simply than Read-Only workload?..
- specially when the data work set is small enough to fit the InnoDB Buffer Pool and remain fully cached?..
- the test case is a simple Sysbench OLTP_RO workload, so nothing surprising here, many times tested by others..
- running the test on both MySQL 5.5 and 5.6, to be sure nothing wrong came with 5.6 code..
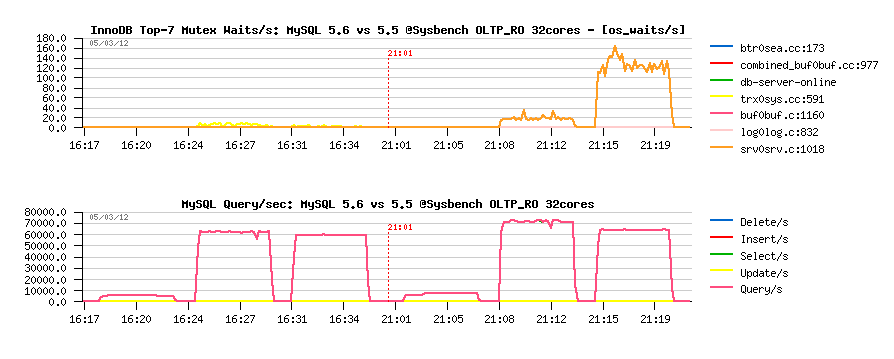
- well, on a single user thread performance numbers may be quite random and vary from test to test..
- but what is blocking any performance increase when we're moving from 16 concurrent users to 32?..
- there are 32cores on the server and from the HW power point there is no limit yet..
- from the SW point: other applications are scaling well on this server, then regarding InnoDB - if on 5.5 it's at least reporting the increased contention on the "kernel_mutex", then on 5.6 it's reporting just nothing!..
- same "problem" with PFS (Performance Schema) - no any increased contention is reported..
We're simply lacking and instrumentation somewhere to find the source of the problem..
So, then I've started a long weeks of testing + in depth code profiling to understand what's going on.. Of course, I did not spend all of my time on resolving only this problem :-)) But you may understand as well than any other issues became less critical in my mind, because when you're hitting such a huge scalability limit without any contentions reported by the code.. - do you worry then about response time in your tests or any other benchmarks?.. - it's just looking like a huge bug or invisible contention.. - you're turning around it.. able to see the impact.. but still cannot see why it happens :-))
Well, to make it shorter - at one point of time a quantity of test results and analyzed cases should move to a quality of the final improvement in the code ;-)) so, when there was a time for our planned Performance Meeting in Paris, there was enough of data to discuss from my side, and this scalability limit was one of the main points in agenda..
Our brainstorming meeting was a true success! And I'd say it's a real pleasure when you're living such kind of events in your life.. - summarized all our skills together, we profiled the code dipper and dipper, arriving finally to assembler level to discover what is going on ;-)) There was such a strong complicity in this teamwork that we quickly understood that we simply MUST fix this issue ;-)) And finally we got it fixed!.. - it was even hard to believe the solution was so close.. Well, generally you know that it may happen in "some cases", but that it happens with MySQL code which is RDBMS and not at all HPC related?? (HPC - High Performance Computing)..
The scalability issue came from the effect that we got some code zones (data structures) in MySQL/InnoDB which became too hot on CPU cacheline!.. I'll not repeat the same details explained by Mikael in his blog post, but rather just will present you few most spectacular graphs comparing performance before and after G5 (the code name we used to call this improvement feature):
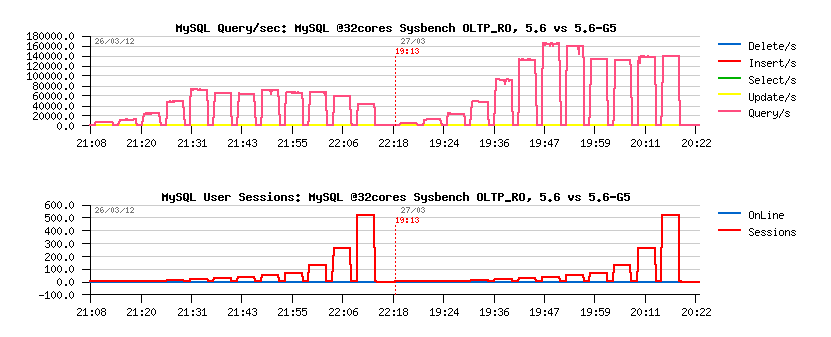
- over 50% performance improvement!.. ;-))
An even more spectacular on Sysbench RO SELECT RANGES test:
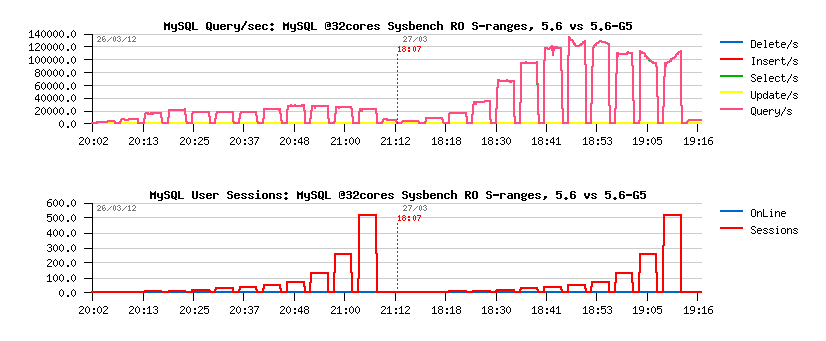
- up to x6 times(!) faster ;-))
All these improvement and many other are available right now within MySQL 5.6-labs release!
what else to say?.. - I'm just proud to be part of it :-)) and enjoying my MySQL "full time" more than ever.. ;-))
Stay tuned, more is coming ;-))
We're living a great time..
Rgds,
-Dimitri
P.S. BTW, did I forget to say you we're hiring @MySQL ?.. ;-))
MySQL Performance: Game Of Contentions..
Recently running yet one of series of benchmark on MySQL 5.6, I've met the following case:
- the workload is Read+Write, 256 concurrent user sessions running non-stop..
- Performance Schema (PFS) is enabled and Synch events are monitored (both counted and timed)..
- accidentally I've not fully disabled the query cache (QC) in MySQL config (query_cache_type=0 was missed)
- and at once PFS reported it to be the top wait event during this workload:
Test #1 -- @5.6 with PFS=on, default query_cache_type:
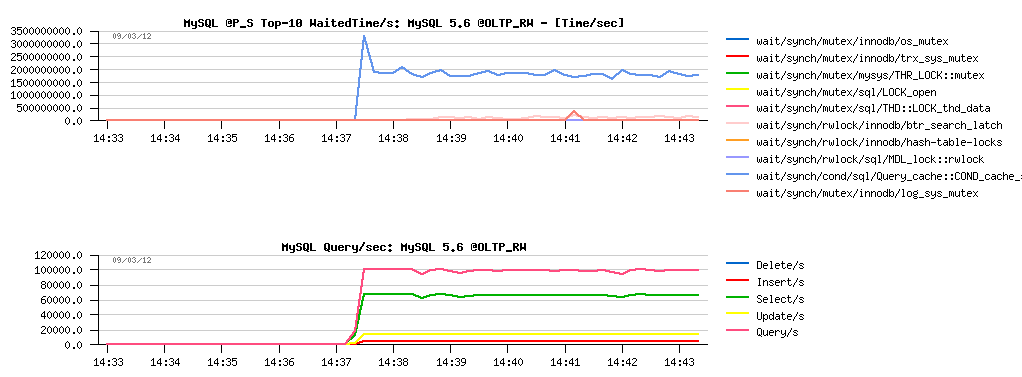
NOTE: we're reaching in this configuration ~100K QPS..
So, of course, I've expected to see much more higher QPS once I've set query_cache_type=0, don' you?.. ;-)
The second graphs are representing the result obtained with these changes:
Test #2 -- @5.6 with PFS=on, query_cache_type=0:
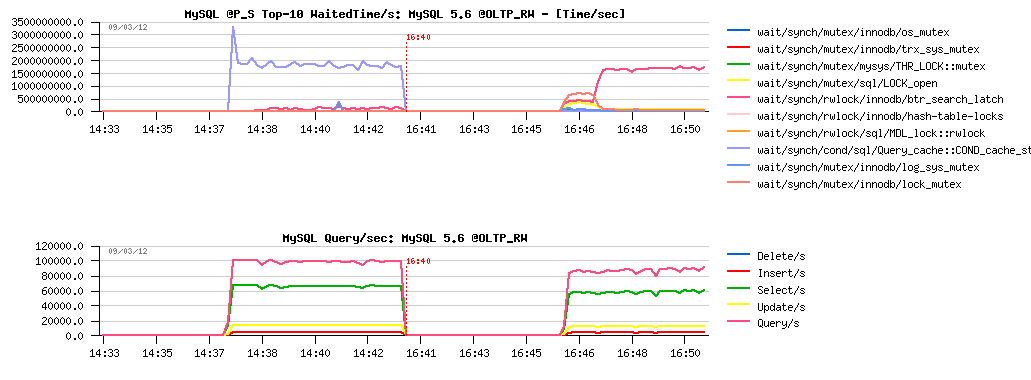
So far:
- 80K-90K QPS instead of 100K QPS observed initially..
- wait time on the "btr_search_latch" lock contention is now replacing the same wait event time as the QC before..
Hm.. - my tuning "improvement" is resulting in a worse performance finally..
But keeping in mind that "btr_search_latch" is a RW-lock (and PFS overhead become higher on hot RW-locks), it's possible to suspect here PFS overhead..
Let's replay with PFS disabled now:
Test #3 -- @5.6 with PFS=off, query_cache_type=0:

Oh! it's much better! - we're reaching 100K QPS again! (well, near reaching 100K, to be honest.. - 98K QPS probably, but well, it seems to be better anyway ;-))
And what if now I'll comment again the "query_cache_type" setting and leave it by default?..
Test #4 -- @5.5 with PFS=off, default query_cache_type:

Hm... - no difference!.. - so, there is no impact at all with QC query_cache_type leaved by default???.. :-))
Let's summarize now:
- 100K QPS with PFS=on, query_cache_type=default
- 90K QPS with PSS=on, query_cache_type=0
- 98K QPS with PFS=off, query_cache_type= default or 0
So far:
- from the last 2 tests: seems that "query_cache_type" setting is not having any performance impact..
- from the first 2 tests: "query_cache_type" has performance impact ;-)
- from the tests #2 and #3: PFS has performance impact when enabled..
- and we still have the best performance result here when PFS is enabled + "query_cache_type" is not turned OFF ;-))
- NOTE: the test workload is exactly the same in all cases..
- NOTE: it's exactly the same MySQL binary used in all cases too, so if PFS has an overhead, it'll be the same one whenever PFS is turned ON.. ;-))
What is wrong here?..
Nothing.. :-)
The problem is that since some time we're entering with MySQL code in a new game of contentions which is very well seen in a presented example:
- PFS overhead is higher whenever RW-lock contention is higher..
- enabling "query_cache_type" is adding an additional overhead (as seen from the Test #1)..
- but this additional overhead by its action is lowering the contention on "btr_search_latch" RW-lock ;-))
- lowering RW-lock contention is reducing on its turn PFS overhead..
- and finally resulting in the better performance, even it sounds surprisingly ;-))
And, finally, the mutex waits seen by InnoDB for all 4 tests are looking like following:

Quite surprising impact on "btr_search_latch" contention ;-))
However, there are many other contentions as well, and this post is just a short example about.. - I'll use it as a reference in following posts this week and in a near future when discussing about various "lock contentions impact" in MySQL ;-))
Rgds,
-Dimitri